论文地址:https://arxiv.org/abs/1906.00817
代码:https://github.com/valeoai/ZS3
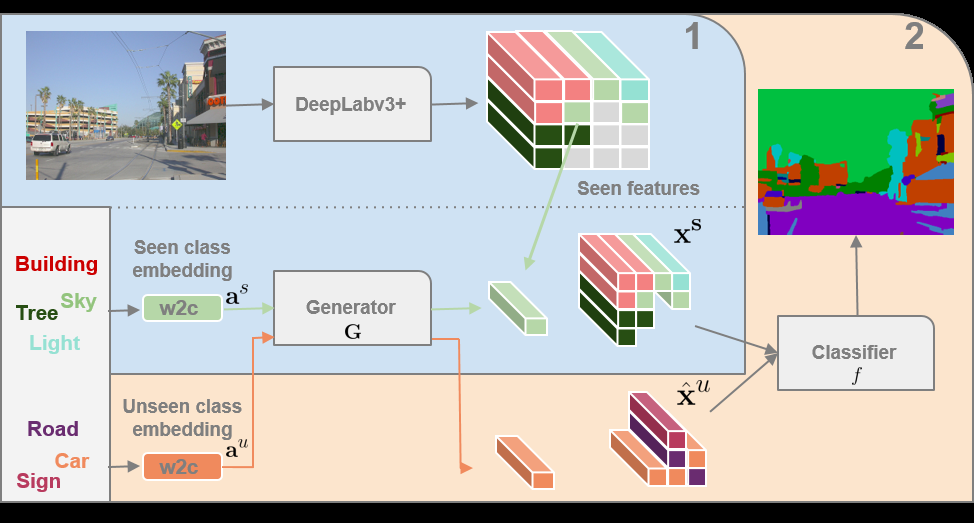
Step 0:首先使用数据集(完全不包含 Unseen Classes 的图片)训练 DeepLabv3+ 模型,得到的模型可以对只含有 Seen Classes 的图片进行分类,去掉训练好的 DeepLabv3+ 的最后一层分类层,将其变成一个特征提取器。将所有 Classes 输入到 w2c 模型,得到每个Class 对应的向量,将此向量连接到 ground-truth 中每个像素上,即每个像素都有其对应的类的向量。
Step 1:使用数据集(完全不包含 Unseen Classes 的图片)输入到 DeepLabv3+ 模型,得到特征图,根据 ground-truth 上的 Class 筛选出不同类别的特征,将每个类的特征作为 Label,对应类的 w2c 输出的向量作为输入,训练 GMMN 模型。
Step 2:使用完整数据集 (包含 Seen 和 Unseen Classes 的图片)输入到 DeepLabv3+ 模型,如果不包含 Unseen Classes,那么直接拿出特征图去训练最终的分类器,如果包含,则根据图片的 ground-truth 对应的类的向量一一生成特征,将不同类特征组合到一起,再去训练最终的分类器。
1. 代码中将 Step 1 和 2 和在了一起,为了便于理解,把 Step 1 和 2 分开解释。
2. Step 2 中使用了两次包含 Unseen Classes 的图像和其 ground-truth。
3. w2c 和 GMMN 是文章的关键,w2c 建立了一个从词语到向量的联系,GMMN 建立了一个从词向量到特征图上的视觉特征的联系,比如,使用 Unseen Class 为子弹,Seen Class 中包括弹匣,其他都是些不相干的类,自然子弹和弹匣在词向量中的联系比较起来相对紧密,从而子弹通过 GMMN 生成的特征也更与弹匣类似,通过最终分类器的训练,也就更容易能分辨出子弹。
