大家好~本文在如何用WebGPU流畅渲染百万级2D物体?基础上进行优化,使用WebGPU实现了Ray Packet,也就是将8*8=64条射线作为一个Packet一起去访问BVH的节点。这样做的好处是整个Packet只需要一个维护BVH节点的Stack,节省了GPU Shared Memory;坏处是一个Packet的64条射线是并行计算的,需要实现同步逻辑,并且针对GPU的架构进行并行优化
相关文章如下:
如何用WebGPU流畅渲染百万级2D物体?
我们渲染1百万个圆环,对比优化前的Demo:
性能指标:
硬件:
每条射线使用一个局部单位,所以一个Packet共使用8*8=64个局部单位
这里将射线与相机近平面的交点变换到了屏幕坐标系下,变量名为pointInScreen(之前的Demo中的交点是在世界坐标系下)
整个算法的相关实现代码如下所示:
var<workgroup>stackContainer: array<TopLevel, 20>;var<workgroup>rayPacketAABBData: array<f32, 4>;var<workgroup>isRayPacketAABBIntersectWithTopLevelNode: bool;var<workgroup>rayPacketRingIntersectLayer: array<u32, 64>;var<workgroup>stackSize: u32;var<workgroup>isAddChild1: bool;var<workgroup>isAddChild2: bool;...fn _intersectScene(ray: Ray, LocalInvocationIndex : u32) -> RingIntersect { var intersectResult: RingIntersect; intersectResult.isClosestHit = false; intersectResult.layer = 0; var rootNode = topLevel.topLevels[0]; var pointInScreen = ray.rayTarget; // 用两个局部单位并行创建Packet的AABB if (LocalInvocationIndex == 0) { rayPacketAABBData[0] = pointInScreen.x; rayPacketAABBData[1] = pointInScreen.y; } if (LocalInvocationIndex == 63) { rayPacketAABBData[2] = pointInScreen.x; rayPacketAABBData[3] = pointInScreen.y; } //用一个局部单位并行初始化共享变量 if (LocalInvocationIndex == 1) { stackSize = 1; stackContainer[0] = rootNode; } workgroupBarrier(); //遍历BVH节点 while (stackSize > 0) { //在循环开始的时候要同步下(暂时不清楚原因,反正是因为stackSize是共享变量造成的) workgroupBarrier(); if (LocalInvocationIndex == 0) { stackSize -= 1; } workgroupBarrier(); var currentNode = stackContainer[stackSize]; var leafInstanceCountAndMaxLayer = u32(currentNode.leafInstanceCountAndMaxLayer); var leafInstanceCount = _getLeafInstanceCount(leafInstanceCountAndMaxLayer); //如果是叶节点,则Packet中所有射线都与该节点进行相交检测 if (_isLeafNode(leafInstanceCount)) { //判断射线是否与节点的AABB相交 if (_isPointIntersectWithTopLevelNode(pointInScreen, currentNode)) { var leafInstanceOffset = u32(currentNode.leafInstanceOffset); var maxLayer = _getMaxLayer(u32(currentNode.leafInstanceCountAndMaxLayer)); //判断射线是否与节点包含的所有圆环相交 while (leafInstanceCount > 0) { var bottomLevel = bottomLevel.bottomLevels[leafInstanceOffset]; //判断射线是否与圆环的AABB相交 if (_isPointIntersectWithAABB(pointInScreen, bottomLevel.screenMin, bottomLevel.screenMax)) { var instance: Instance = sceneInstanceData.instances[u32(bottomLevel.instanceIndex)]; var geometry: Geometry = sceneGeometryData.geometrys[u32(instance.geometryIndex)]; //判断射线是否与圆环相交 if (_isIntersectWithRing(pointInScreen, instance, geometry)) { var layer = u32(bottomLevel.layer); if (!intersectResult.isClosestHit || layer > intersectResult.layer) { intersectResult.isClosestHit = true; intersectResult.layer = layer; intersectResult.instanceIndex = bottomLevel.instanceIndex; } } } leafInstanceCount = leafInstanceCount - 1; leafInstanceOffset = leafInstanceOffset + 1; } } } //如果不是叶节点,则通过剔除检测后加入两个子节点 else { // 一个非叶节点必有两个子节点 var child1Node = topLevel.topLevels[u32(currentNode.child1Index)]; var child2Node = topLevel.topLevels[u32(currentNode.child2Index)]; var child1NodeMaxLayer = _getMaxLayer(u32(child1Node.leafInstanceCountAndMaxLayer)); var child2NodeMaxLayer = _getMaxLayer(u32(child2Node.leafInstanceCountAndMaxLayer)); //并行计算Packet中所有射线的最小layer rayPacketRingIntersectLayer[LocalInvocationIndex] = intersectResult.layer; workgroupBarrier(); if (LocalInvocationIndex < 32) { _minForRayPacketRingIntersectLayer(LocalInvocationIndex, LocalInvocationIndex + 32); } workgroupBarrier(); if (LocalInvocationIndex < 16) { _minForRayPacketRingIntersectLayer(LocalInvocationIndex, LocalInvocationIndex + 16); } workgroupBarrier(); if (LocalInvocationIndex < 8) { _minForRayPacketRingIntersectLayer(LocalInvocationIndex, LocalInvocationIndex + 8); } workgroupBarrier(); if (LocalInvocationIndex < 4) { _minForRayPacketRingIntersectLayer(LocalInvocationIndex, LocalInvocationIndex + 4); } workgroupBarrier(); if (LocalInvocationIndex < 2) { _minForRayPacketRingIntersectLayer(LocalInvocationIndex, LocalInvocationIndex + 2); } workgroupBarrier(); //用两个局部单位并行判断子节点是否在Packet的前面以及Packet的AABB是否与子节点相交 if (LocalInvocationIndex == 0) { isAddChild1 = child1NodeMaxLayer > rayPacketRingIntersectLayer[0] && _isRayPacketAABBIntersectWithTopLevelNode(rayPacketAABBData, child1Node); } if (LocalInvocationIndex == 1) { isAddChild2 = child2NodeMaxLayer > rayPacketRingIntersectLayer[0] && _isRayPacketAABBIntersectWithTopLevelNode(rayPacketAABBData, child2Node); } workgroupBarrier(); // 加入两个子节点到stack中 if (LocalInvocationIndex == 0) { if (isAddChild1) { stackContainer[stackSize] = child1Node; stackSize += 1; } if (isAddChild2) { stackContainer[stackSize] = child2Node; stackSize += 1; } } } workgroupBarrier(); } return intersectResult;}“创建Packet的AABB”代码说明

如上图所示,红色方块为Packet的2D AABB,由64个射线的pointInScreen组成
图中蓝色方块为一个pointInScreen,从中心点开始
pointInScreen对应的局部单位序号是从红色方块左下角开始,朝着右上方增加。
部分局部单位序号在图中用数字标注了出来
所以Packet的2D AABB的min即为0号局部单位对应的pointInScreen,而max则为63号局部单位对应的pointInScreen
创建Packet的AABB的相关代码如下:
var pointInScreen = ray.rayTarget; // 用两个局部单位并行创建Packet的AABB if (LocalInvocationIndex == 0) { rayPacketAABBData[0] = pointInScreen.x; rayPacketAABBData[1] = pointInScreen.y; } if (LocalInvocationIndex == 63) { rayPacketAABBData[2] = pointInScreen.x; rayPacketAABBData[3] = pointInScreen.y; }因为现在需要对一个Packet中64条射线并行计算,所以需要了解GPU的架构和特点,从而进行相应的优化
GPU是以warp为单位,每个wrap包含32个线程。所以我们这里的一个Packet应该使用了两个wrap,其中一个wrap中的一个线程对应一个局部单位
并行计算的优化点为:
只有当整个wrap中所有线程都不执行某个操作时,这个wrap才不会被执行,从而FPS会提高。只要wrap中至少有一个线程要执行某个操作,那么即使其它所有线程不执行该操作,它们也会在执行"workgroupBarrier()"时等待)
GPU中Memory IO是个瓶颈,所以应该减少内存读写操作
GPU内存类型分为寄存器、共享、局部、常量、纹理、全局,读写速度依次递减
内存模型如下图所示: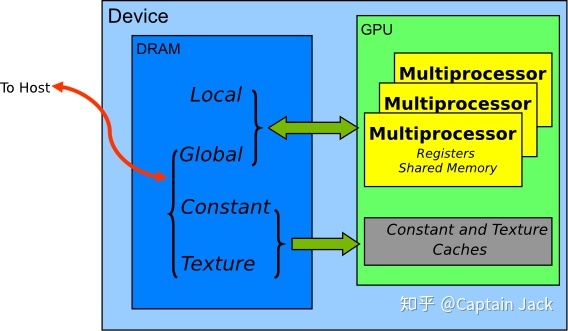
内存特性如下图所示:
应该减少速度慢的局部、常量、纹理、全局内存的读写
减少bank conflict
共享内存是由多个bank组成,对于同一个bank的不同地址的读写会造成bank conflict
因此尽量读写共享内存的连续地址
减少wrap diverse
应该减少一个Packet中不同的局部单位进入不同的if分支的情况(这会造成局部单位阻塞)
之前的Demo使用串行算法,而现在的Demo使用并行算法
如果都不使用traverse order优化(即判断节点如果在射线的后面,则不遍历它),则FPS提升了50%;
如果都使用traverse order优化,则FPS没有变化;
这说明traverse order优化对于串行算法的提升更大。这是因为对于并行算法而言,只有当节点在一个Packet的所有射线的后面时,才不会遍历节点(可以参考之前的提到的优化点1);
而对于串行算法而言,只要当节点在一条射线的后面,就不会遍历节点
通过Large Ray Packets for Real-time Whitted Ray Tracing论文,得知现在的并行算法属于文中提到的“Masked traversal”算法
文中还介绍了改进版的Ranged traversal算法,具体就是指一个Packet增加first active和last active标志,从而使一个Packet中只有first到last之间的射线进行相交检测,减少了相交检测的射线数量
但是这个算法应用到本文的并行算法中并不会提高FPS!因为本文的并行算法中的一个Packet至少会有一条射线会与叶节点进行相交检测,所以根据之前提到的优化点1可知FPS不会提高
现在我们对代码进行一些具体的分析:
寄存器、共享、局部、全局内存分析
参考代码与存储的映射关系:
以及参考gpu cpu 共享内存 提高传输速度_GPU编程3--GPU内存深入了解,我们来分析下本文部分代码中的内存使用情况:
fn _intersectScene(ray: Ray, LocalInvocationIndex : u32) -> RingIntersect { //intersectResult是较大结构体,应该位于局部内存 var intersectResult: RingIntersect; intersectResult.isClosestHit = false; intersectResult.layer = 0; //topLevel.topLevels是storage buffer数据,位于全局内存 //rootNode是较大结构体,应该位于局部内存 var rootNode = topLevel.topLevels[0]; //pointInScreen位于寄存器 var pointInScreen = ray.rayTarget; if (LocalInvocationIndex == 0) { //rayPacketAABBData位于共享内存 rayPacketAABBData[0] = pointInScreen.x; rayPacketAABBData[1] = pointInScreen.y; } if (LocalInvocationIndex == 63) { rayPacketAABBData[2] = pointInScreen.x; rayPacketAABBData[3] = pointInScreen.y; } ...}GPU Memory IO优化
根据之前提到的优化点2,我们知道应该减少GPU内存的读写,特别是全局内存的读写
我们来对照代码分析一下全局内存读写的优化,看下面的代码:
var rootNode = topLevel.topLevels[0];...if (LocalInvocationIndex == 1) { stackSize = 1; stackContainer[0] = rootNode;}这里一个Packet中所有局部单位都从全局内存中读取第一个元素为rootNode,写到本地内存中(这里进行了64次全局内存读操作);
然后在1号局部单位中,从本地内存中读取rootNode,写到共享内存中
如果将代码改为:
if (LocalInvocationIndex == 1) { stackSize = 1; stackContainer[0] = topLevel.topLevels[0];}那么就应该只进行1次全局内存读操作,从而提高FPS
但是实际上却降低了10%左右FPS,这是为什么呢?
这是因为GPU会将对全局内存同一地址或者相邻地址的读操作合并为一次操作(写操作也是一样),所以修改前后的代码对全局内存的读操作都是1次。
那么FPS应该不变,但为什么下降了呢?
这是因为在进行内存操作时,需要加上事务(进行锁之类的同步操作)。如果一个wrap中的所有线程同时对全局内存的一个地址进行读,则合并后的该次操作只需要一个事务;而如果是一个wrap中的部分线程进行读,则合并后的该次操作需要更多的事务(如4个),从而需要更多时间开销,降低了FPS
参考资料:
Nvidia GPU simultaneous access to a single location in global memory
初识事务内存(Transactional Memory)
我们再看下面的代码:
else { var child1Node = topLevel.topLevels[u32(currentNode.child1Index)]; var child2Node = topLevel.topLevels[u32(currentNode.child2Index)]; var child1NodeMaxLayer = _getMaxLayer(u32(child1Node.leafInstanceCountAndMaxLayer)); var child2NodeMaxLayer = _getMaxLayer(u32(child2Node.leafInstanceCountAndMaxLayer));这里只需要一次合并后的读操作,从全局内存中读出child1Node、child2Node
如果代码改为:
else { var child1Node = topLevel.topLevels[u32(currentNode.child1Index)]; var child1NodeMaxLayer = _getMaxLayer(u32(child1Node.leafInstanceCountAndMaxLayer)); var child2Node = topLevel.topLevels[u32(currentNode.child2Index)]; var child2NodeMaxLayer = _getMaxLayer(u32(child2Node.leafInstanceCountAndMaxLayer));因为要切换内存(全局和局部内存之间切换),所以就不能合并了,而需要二次全局内存的读操作,分别读出child1Node和child2Node,所以FPS会下降10%左右
parallel reduction优化并没有提高FPS
下面的代码使用了parallel reduction的优化版本来并行计算Packet中所有射线的最小layer:
if (LocalInvocationIndex < 32) { _minForRayPacketRingIntersectLayer(LocalInvocationIndex, LocalInvocationIndex + 32); } workgroupBarrier(); if (LocalInvocationIndex < 16) { _minForRayPacketRingIntersectLayer(LocalInvocationIndex, LocalInvocationIndex + 16); } workgroupBarrier(); if (LocalInvocationIndex < 8) { _minForRayPacketRingIntersectLayer(LocalInvocationIndex, LocalInvocationIndex + 8); } workgroupBarrier(); if (LocalInvocationIndex < 4) { _minForRayPacketRingIntersectLayer(LocalInvocationIndex, LocalInvocationIndex + 4); } workgroupBarrier(); if (LocalInvocationIndex < 2) { _minForRayPacketRingIntersectLayer(LocalInvocationIndex, LocalInvocationIndex + 2); } workgroupBarrier();关于parallel reduction优化可以参考啥是Parallel Reduction
优化后的代码并不比下面的原始版本的代码快:
for (var s: u32 = 1; s < 64; s = s * 2) { if (LocalInvocationIndex % (2 * s) == 0) { _minForRayPacketRingIntersectLayer(LocalInvocationIndex, LocalInvocationIndex + s); } workgroupBarrier();}估计是GPU帮我们优化了
wrap diverse优化
在之前使用串行算法的Demo代码中,我们在遍历叶节点包含的所有圆环时,加入了“如果找到了最前面的相交圆环,则退出叶节点的遍历”的优化,相关代码为:
if (_isLeafNode(leafInstanceCount)) { ... while (leafInstanceCount > 0) { ... if (_isPointIntersectWithAABB(point, bottomLevel.worldMin, bottomLevel.worldMax)) { ... if (_isIntersectWithRing(point, instance, geometry)) { if (!intersectResult.isClosestHit || layer > intersectResult.layer) { ... if(layer == maxLayer){ break; } } } } ... }而在本文的使用并行算法的代码,却删除了这个优化,FPS反而提升了10%。这是因为Packet中只有部分的局部单位会退出遍历,造成其它局部单位阻塞等待
注:如果并行算法的代码要加入这个优化,那也不能直接break,而是改为设置isBreak=true,在if中判断isBreak,这样才不会有同步的问题
bank conflict优化
现代显卡实现了broadcast机制,从而对同一个bank的相同地址的读写不会造成bank conflict。但由于我的测试显卡是老显卡,还没有该机制,所以在这种情况下会造成bank conflict
如下面代码所示:
if (LocalInvocationIndex == 0) { isAddChild1 = _isRayPacketAABBIntersectWithTopLevelNode(rayPacketAABBData, child1Node); } if (LocalInvocationIndex == 1) { isAddChild2 = _isRayPacketAABBIntersectWithTopLevelNode(rayPacketAABBData, child2Node); }两个局部单位同时读共享变量rayPacketAABBData,从而造成bank conflict,FPS下降5%左右
如何用WebGPU流畅渲染百万级2D物体?
WebGPU的计算着色器实现冒泡排序
啥是Parallel Reduction
Ray Tracing学习之Traversal
Real-time Ray Tracing
Fast Ray Tracing
Large Ray Packets for Real-time Whitted Ray Tracing
Realtime Ray Tracing on GPU with BVH-based Packet Traversal
Getting Rid of Packets
is early exit of loops on GPU worth doing?
issue while using break statement in cuda kernel
CUDA——SM中warp调度器调度机制&&访存延迟隐藏
GPU 硬件层次和调度方式
What's the mechanism of the warps and the banks in CUDA?
CUDA之Shared memory bank conflicts详解
gpu cpu 共享内存 提高传输速度_GPU编程3--GPU内存深入了解
欢迎来到Wonder~
扫码加入我的QQ群:

扫码加入免费知识星球-YYC的Web3D旅程:

扫码关注微信公众号:

