HBase基于Google的BigTable论文而来,是一个分布式海量列式非关系型数据库系统,可以提供大规模数据集的实时随机读写。
下面通过一个小场景认识HBase存储。同样的一个数据
用Mysql存储是这样的:
| id | name | age | salary | job |
|---|---|---|---|---|
| 1 | 小明 | 23 | 学生 | |
| 2 | 小红 | 1000 | 律师 |
如果是HBase的话,存储是类似这样列式存储的:
| field1 | filed2 |
|---|---|
| rowkey:1 | name:小明 |
| rowkey:1 | age:23 |
| rowkey:1 | job:学生 |
| rowkey:2 | name:小红 |
| rowkey:2 | salary:1000 |
| rowkey:2 | job:律师 |
HBase这样存储的优点是:
总结:HBase适合海量明细数据的存储,并且后期能有很好的查询性能(单表超千万、上亿,且并发要求高)
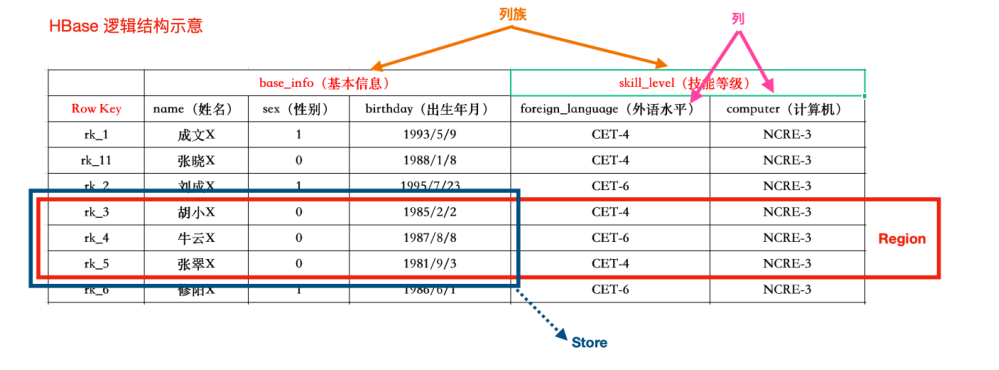
HBase逻辑结构
HBase物理存储
HBase存储的时候是以列族为单位进行存储的。
命名空间,类似于关系型数据库的database概念。每个namespace下有多个表。HBase两个自带的namespace,分别是hbase和default,hbase中存放的是HBase内置的表,default表是用户默认使用的namespace。一个表可以自由选择是否有namespace,如果创建表的时候加了namespace,这个表名字以:作为区分
类似于关系型数据库的表的概念。不同的是,HBase定义表时只需要声明列族即可,数据属性:如超时时间、压缩算法等,都在列族的定义中定义,不需要声明具体的列
HBase表中的每行数据都由一个RowKey和多个Column列组成。一个行包含了多个列,这些列通过列族来分类,行中的数据所属列族只能从表所定义的列族中选取
Rowkey由用户指定的一串不重复的字符串定义,是一行的唯一标识。数据是按照Rowkey的字典顺序存储的,并且查询数据时只能根据Rowkey进行检索,所以Rowkey的设计十分重要。如果使用了之前已经定义的RowKey,那么会将之前的数据更新掉
列族是多个列的集合,一个列族可以动态灵活的定义多个列。表的相关属性大部分都定义在列族上,同一个表里的不同列族可以有完全不同的属性配置,但是同一个列族内的所有列都会有相同的属性。列族存在的意义是HBase会把相同列族的列尽量放在同一台机器上。
HBase中的列是可以随意定义的,一个行中的列不限名字、不限数量、只限定列族。因此列必须依赖于列族存在。列的名称前必须带着所属的列族
用于标识数据的不同版本,时间戳默认由系统指定,也可以用户显式指定。在读取数据的单元格时,版本号可以忽略,如果不指定,HBase默认会获取最后一个版本的数据返回
一个列中可以存储多个版本的数据。而每个版本就称为一个单元格
HBase 将表中的数据基于RowKey的不同范围划分到不同Region上,每个Region都负责一定范围的数据存储和访问。每个表一开始只有一个Region,随着数据不断插入表,Region不断增大,当增大到一个阀值的时候,Region就会等分成两个新的Region。当table中的行不断增多,就会有越来越多的Region。
HBase整体架构
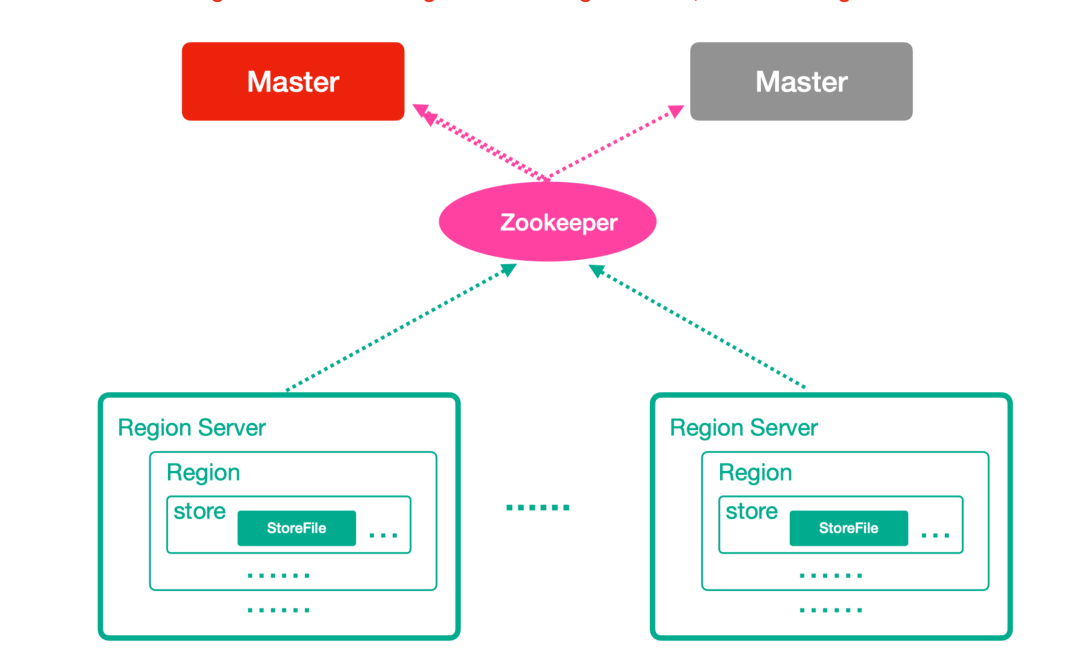
Zookeeper
HMaster(Master)
HRegionServer(RegionServer)
Region
