前段时间我需要实现大文件上传的需求,在网上查找了很多资料,并且也发现已经有很多优秀的博客讲了大文件上传下载这个功能。
我的项目是个比较简单的项目,并没有采用特别复杂的实现方式,所以我这篇文章的目的主要是讲如何最简单地实现大文件上传与下载这个功能,不会讲太多原理之类的东西。
在实际场景中,上传大文件主要会遇到的问题有:
业界最普遍的方案就是切片上传,简单地说就是把文件切割成若干个小文件,再将小文件们传输到后端,最后按照顺序把小文件们重新拼成这个大文件。
所以具体的实现逻辑如下:
把大文件进行切片,对切片的文件内容进行加密生成一个标识串,用于标识唯一的切片
服务端在临时目录里保存各段文件
浏览器端所有分片上传完成,发送给服务端一个合并文件的请求
服务端根据分片顺序进行文件合并
删除分片文件
也有其他合并文件的方式,本文不做讨论,详情可以参考如何做大文件上传。
前端需要做的部分是:
在这里我使用了一个开源库react-chunk-upload,它提供了加密文件函数和获取文件的相应切片内容的函数(如图),这就不用我自己写啦(偷懒小技巧)。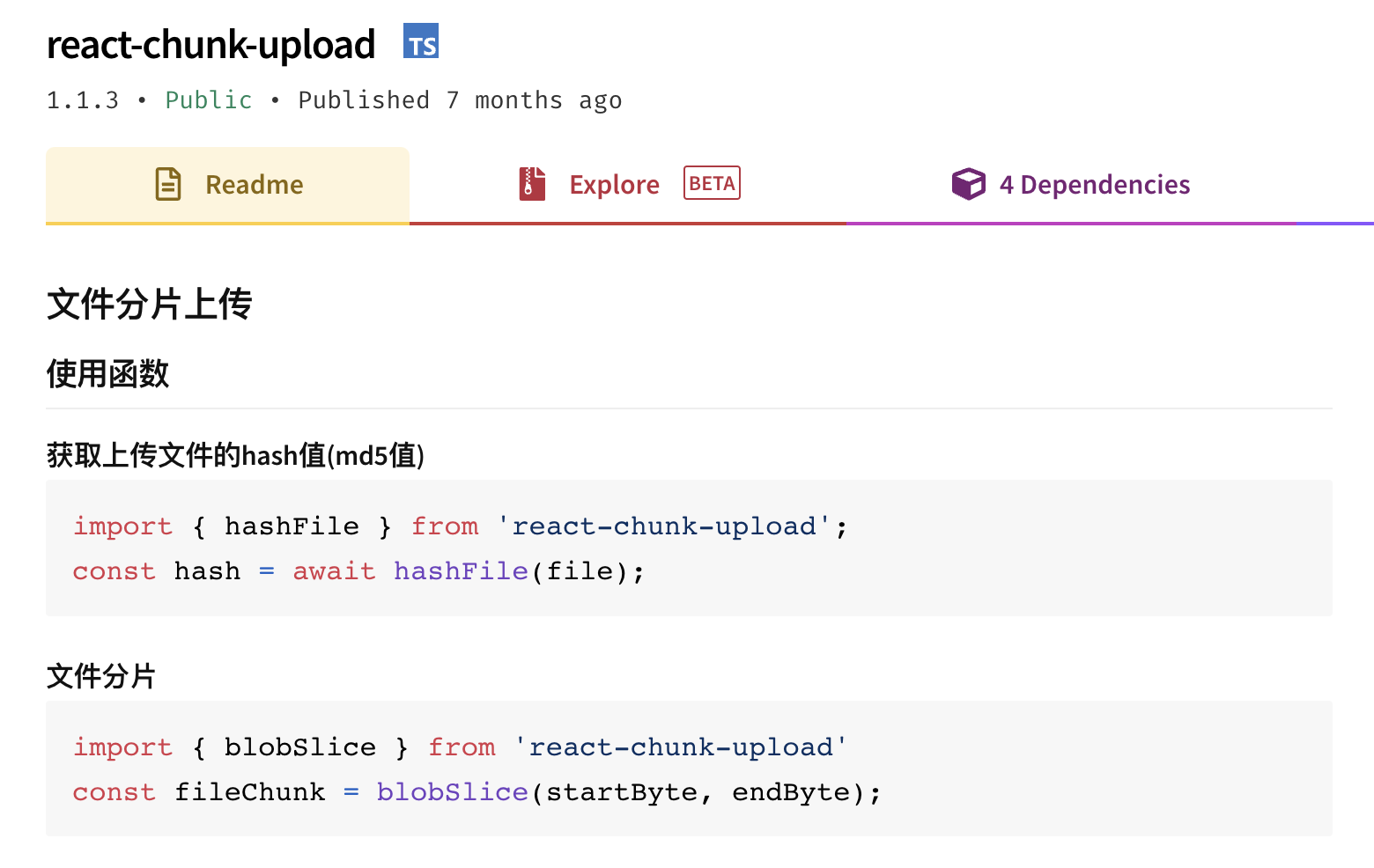
那么前端部分完整的代码如下:
const [uploadProgress, setUploadProgress] = useState(0);const [uploadText, setUploadText] = useState("");const CHUNK_SIZE = 3 * 1024 * 1024; // 设置切片大小为 3Mbconst chunkMD5List = [];const chunkNum = Math.ceil(file.size / CHUNK_SIZE);for (let i = 0; i < chunkNum; i++) { const start = i * CHUNK_SIZE; // 切片的开始位置 const end = Math.min(file.size, start + CHUNK_SIZE); // 切片的结束位置 const chunkBlob = blobSlice.call(file, start, end); // 获取相应位置的切片文件 const chunkFile = new File([chunkBlob], "file", { lastModified: file.lastModified, }); const md5 = await hashFile(chunkFile, CHUNK_SIZE); // 获取切片标识符 chunkMD5List.push(md5); await beforeUploadCheckApi(md5) // 上传前检查这个切片是否已存在的接口 .then(async (res) => { if (res.code === SUCCESS_CODE) { if (!res.data.exist_status) { // 如果不存在才上传 await uploadChunkCSVApi(chunkFile, md5).then((res) => { // 上传切片的接口 if (res.code === SUCCESS_CODE) { const progress = Math.floor(((i + 1) / chunkNum) * 10000) / 100; // 计算上传进度,这里为了更好的用户体验,我特意预留了3%给最后的合并文件步骤 setUploadProgress(progress < 3 ? 0 : progress - 3); } }); } else { const progress = Math.floor(((i + 1) / chunkNum) * 10000) / 100; setUploadProgress(progress < 3 ? 0 : progress - 3); } } }) .catch(() => { setUploadText("上传失败"); });}mergeChunkApi(f.name, JSON.stringify(chunkMD5List)) // 合并切片的接口 .then((res) => { if (res.code === SUCCESS_CODE) { setUploadText(`上传 ${file.name} 成功`); setUploadProgress(100); // 合并文件需要一些时间,所以合并完再让进度条到100 }}) .catch(() => { setUploadText(`合并保存文件失败`);});后端需要提供三个接口,分别是:
前两个接口的逻辑都很简单,第一个接口是判断文件目录是否存在,第二个接口是把文件放到指定目录。
第三个接口的合并逻辑也不难,就是按照顺序读取切片文件然后写入,代码如下:
// 创建一个空文件filePath := ".....省略"f, err := os.OpenFile(filePath, os.O_CREATE|os.O_WRONLY|os.O_APPEND, os.ModePerm)if err != nil { fmt.Println("打开文件失败: %v", err)}chunkMD5Array := []string{}```前端需要传给后端一个切片名称的有序数组,此处省略具体处理过程```for _, chunkMD5 := range chunkMD5Array { chunkPath := fmt.Sprintf("/temp/%v", chunkMD5) chunk, err := os.Open(chunkPath) if err != nil { fmt.Println("打开文件的切片 %v 内容失败: %v", chunkMD5, err) } content, err := ioutil.ReadAll(chunk) if err != nil { fmt.Println("读取文件的切片 %v 内容失败: %v", chunkMD5, err) } _, err = f.Write(content) if err != nil { fmt.Println("写入文件的切片 %v 内容失败: %v", chunkMD5, err) } chunk.Close()}// 写入完毕,关闭文件f.Close()// 合并后删除切片文件for _, chunkMD5 := range chunkMD5Array { chunkPath := fmt.Sprintf("/temp/%v", chunkMD5) err := os.RemoveAll(chunkPath) if err != nil { fmt.Println("删除切片文件%v失败:%v", chunkMD5, err) }}大文件上传就这么简单地搞定了,并且这个实现方法虽然不是断点续传,但是也会大大提高文件的上传速度。
大文件下载的方案则需要区分两种情况:
①window.open方法
②分片下载
其余的下载方式,例如a标签下载、表单下载等,都适用于较小文件,这里不讨论。
window.open方法使用window.open方法有一个前提条件:后端接口返回的是文件流。那么用window.open去开启一个新窗口打开这个链接,浏览器就会去处理下载的过程。前端的示例代码如下:
window.open('http://xxxxxxxxxx', '_blank')需要注意的地方是后端接口需要指定请求的Content-Disposition属性。
在常规的HTTP应答中,
Content-Disposition响应头指示回复的内容该以何种形式展示,是以内联的形式(即网页或者页面的一部分),还是以附件的形式下载并保存到本地——来源 MDN(https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Content-Disposition)
window.open不会下载文件,而会预览文件,行为不符合预期。分片下载的逻辑类似于上文所提到的切片上传,具体的实现逻辑如下:
前端代码按照实现思路来讲,可以实现为四个函数:
blobblobblob为文件在这里,我把这个流程封装为了一个开源库react-chunks-to-file,提供后端的接口地址即可完成下载操作。
示例代码:
// 进度const [percent, setPercent] = useState<number>();// 状态const [status, setStatus] = useState<number>();return( <ChunksDownload reqSetting={{ getSizeAPI: `${APP_DOMAIN}/csv/size?`, // 获取文件大小的接口url getSizeParams: { token: getToken(), id: csvId, }, chunkDownloadAPI: `${APP_DOMAIN}/csv/download_chunk?`, // 下载分片文件的接口url chunkDownloadParams: { token: getToken(), id: csvId, }, }} fileName={csv.csv_name} mime={"text/csv"} // 文件类型 size={3} // 分片大小 concurrency={5} // 并发数 setStatus={setStatus} setPercent={setPercent} style={{ display: "inline" }} > <Button type="link" onClick={() => downloadCSV(csv.csv_name)} > 下载 </Button> </ChunksDownload>);blob,不同浏览器对可以下载的文件大小有限制,比如Chrome里是2GBreact-chunks-to-file介绍后端主要是提供两个接口:获取文件大小和下载文件的切片。
也可以合为一个接口,文件大小从请求 header 中的 Content-Length 里获取。
获取文件大小很简单,省略不讲。下面是下载文件切片的示例请求: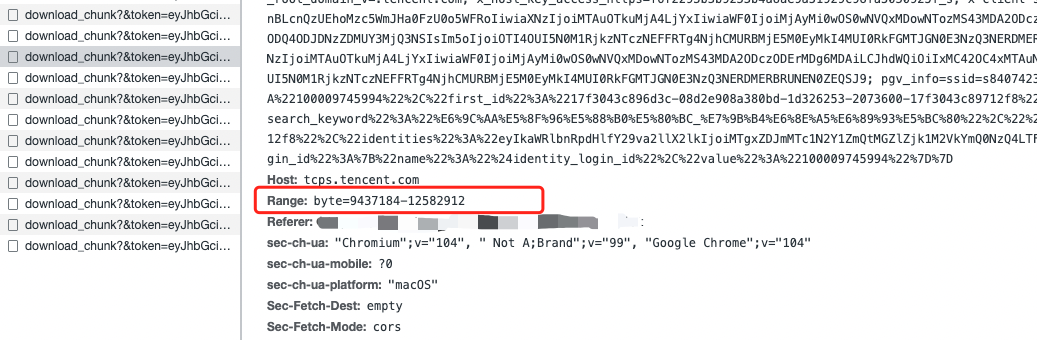
后端接口从Range里得知要提供文件的什么范围的切片数据。读取指定位置的文件用Go实现的示例代码如下:
// GetFileChunk 获取指定位置的文件片段func GetFileChunk(filePath string, start, end int64) ([]byte, error) { f, err := os.Open(filePath) if err != nil { return nil, err } // 跳转文件到指定位置 _, err = f.Seek(start, 0) if err != nil { return nil, err } // 读取指定长度的文件 byteSlice := make([]byte, end-start) _, err = f.Read(byteSlice) if err != nil { return nil, err } return byteSlice, nil}但是HTTP请求已经默认实现了这部分,不需要再自己实现,代码仅供参考。
如何做大文件上传
JavaScript 中如何实现大文件并行下载?
一文带你层层解锁「文件下载」的奥秘
