
MySQL的SQL语句执行流程(简述)
导言:
MySQL和服务器端对接的时候,我们知道一般就是服务器端会打包一些SQL命令去增删改查数据库,这个打包的数据库SQL语句数据包一般为4MB,再大一些就不会被数据库端接收了
但是我们可以自己更改默认大小,当数据包到达数据库端以后,它们会经历那些操作然后返回结果给服务器端呢?
大概有:查询缓存,SQL解析,预处理器,SQL优化器,执行器,存储引擎,返回结果给服务器端
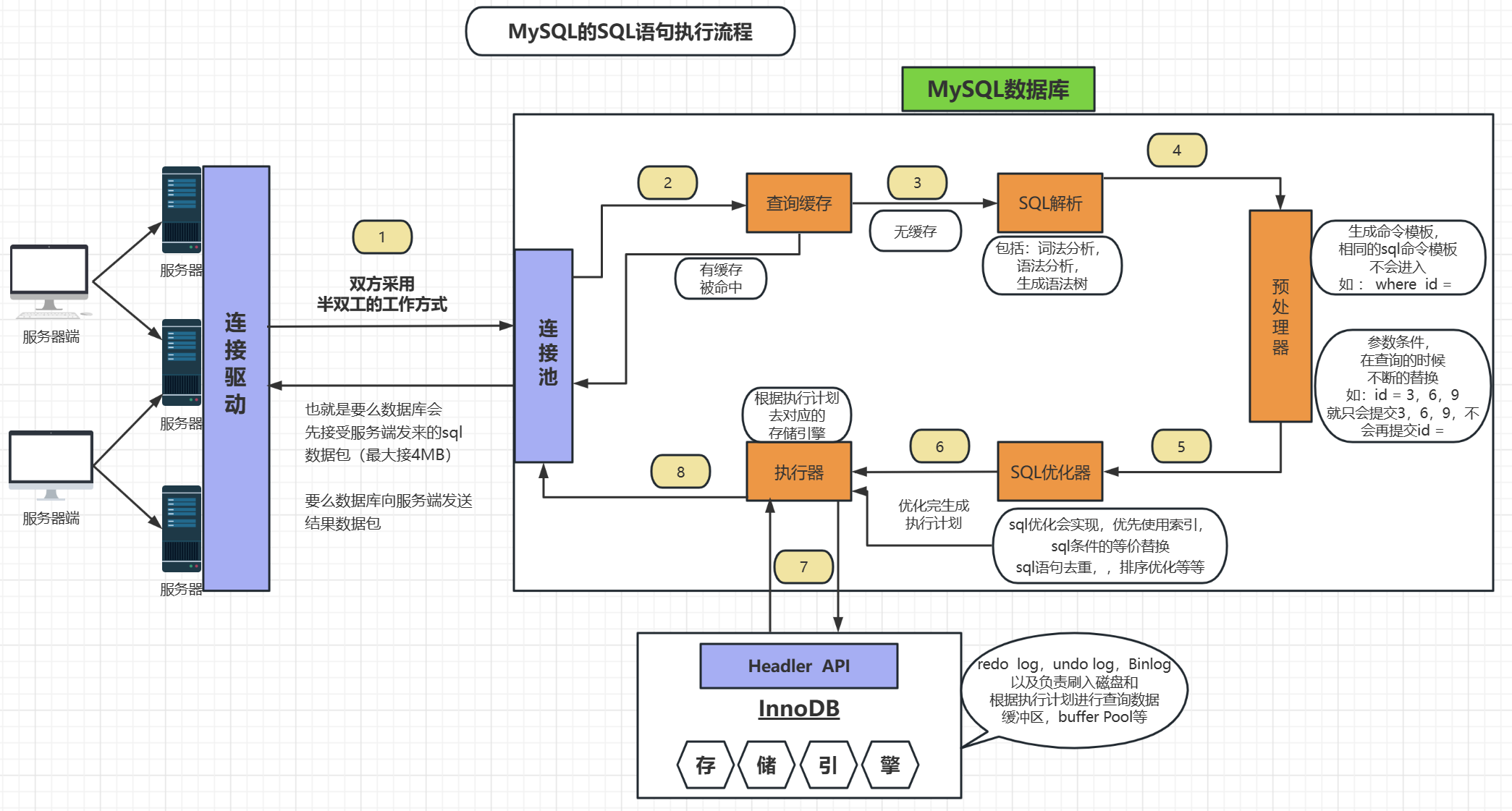
上面就是sql命令的整体执行流程,接下来我们对各个步骤进行拆分,细化的讲解一下他们都做了些什么操作
一.连接
在服务器端和数据库端的连接方式中,我们采用的是半双工的方式,也就是说要么是一次申请到达数据库端,要么是一次结果响应到服务器端
不存在一个数据包还没全部到数据库端,它的结果已经开始响应到服务器的情况
另外,作为第三方连接,我们一般都是使用的数据库连接池,数据库端一般会提供很多的连接接口,供服务器端不同的用户去连接,使用完了然后释放
既然作为第三方连接,它就会使用到数据库驱动,就像JDBC,C3P0等等
此外,数据库一次接收服务器端发来的数据包大概有4MB,多了它就选择不接受了,当然我们也可以自己更改默认接收包的大小
在数据查询完了,返回结果给服务器端也是,它只能一次全部接收,不能只接受一部分结果响应
二.查询缓存
MySQL的缓存是一个很鸡肋的东西,它很少用,但是要想了解底层就必须知道它,它的存在很鸡肋,也导致使用它的很少
数据缓存指的是对已经查询过的数据放在缓存中,下次sql命令来了以后先查询缓存中有没有已经查过的,没有才会去执行新的一次查询,有则直接返回给服务器端
缓存的构成是Map集合,他有两个属性组成,key和value ,key用来存放sql语句,而value用来存放查询的结果
看起来使用缓存会提升查询的效率,但是真正到实战开发以后就会知道,它并没有那么好用,首先一般我们的查询语句都是不同的,很难连续两次的sql完全一样,最好的情况也是条件相差不大
但是也是达不到完全吻合key值的sql,所以实战开发使用效率十分低,伴随着的就是它的缺点,因为它是sql执行的第一个操作,每个sql进来的都要去找一遍,但是都是找不到的
白白的浪费了这么多的开销,而且每一次对数据库的增删改都会影响这个缓存,使其失效,维护又是很大的开销
所以在MySQL 5.7版本是默认关闭这个缓存的,他会跳过查询缓存这一步直接sql解析,到了MySQL8.0的时候直接把查询缓存删掉了,不再需要这个功能了
三.SQL解析
sql解析执行包括了:词法分析,语法分析,分析机,生成语法树
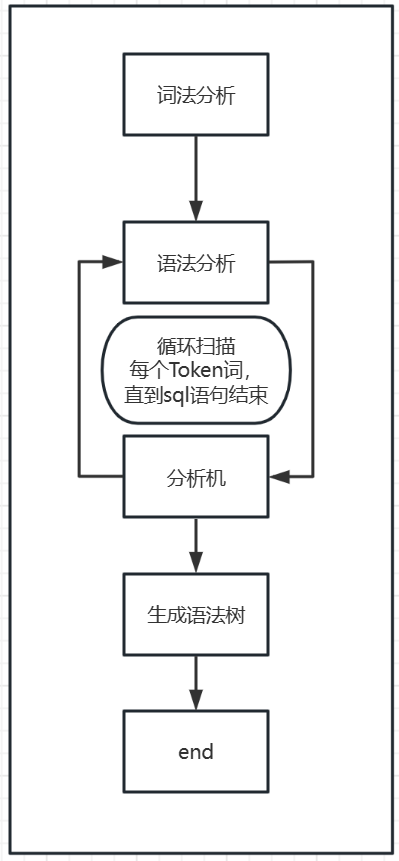
词法分析:从左到右一个字符、一个字符地输入,然后根据构词规则识别单词。将会生成Token词
在进行了词法分析以后,他会把sql默认扫描成两个部分,一个是关键字(select,insert,from,where,group by .......)一个是非关键字(查询的字段,查询的表,查询的筛选条件,分组条件)
语法分析,分析机:它们两个是一起工作的,它们对词法分析生成的Token词开始循环构造语法树,直到整个SQL语句扫描完成了,就构成了一棵语法树
值得注意的是,当MySQL中我们的关键字写错了以后会在词法分析阶段报错,当我们没有加上表名,或条件等格式错误了会在语法分析阶段报错
生成语法树:由每次分析机的输出构成
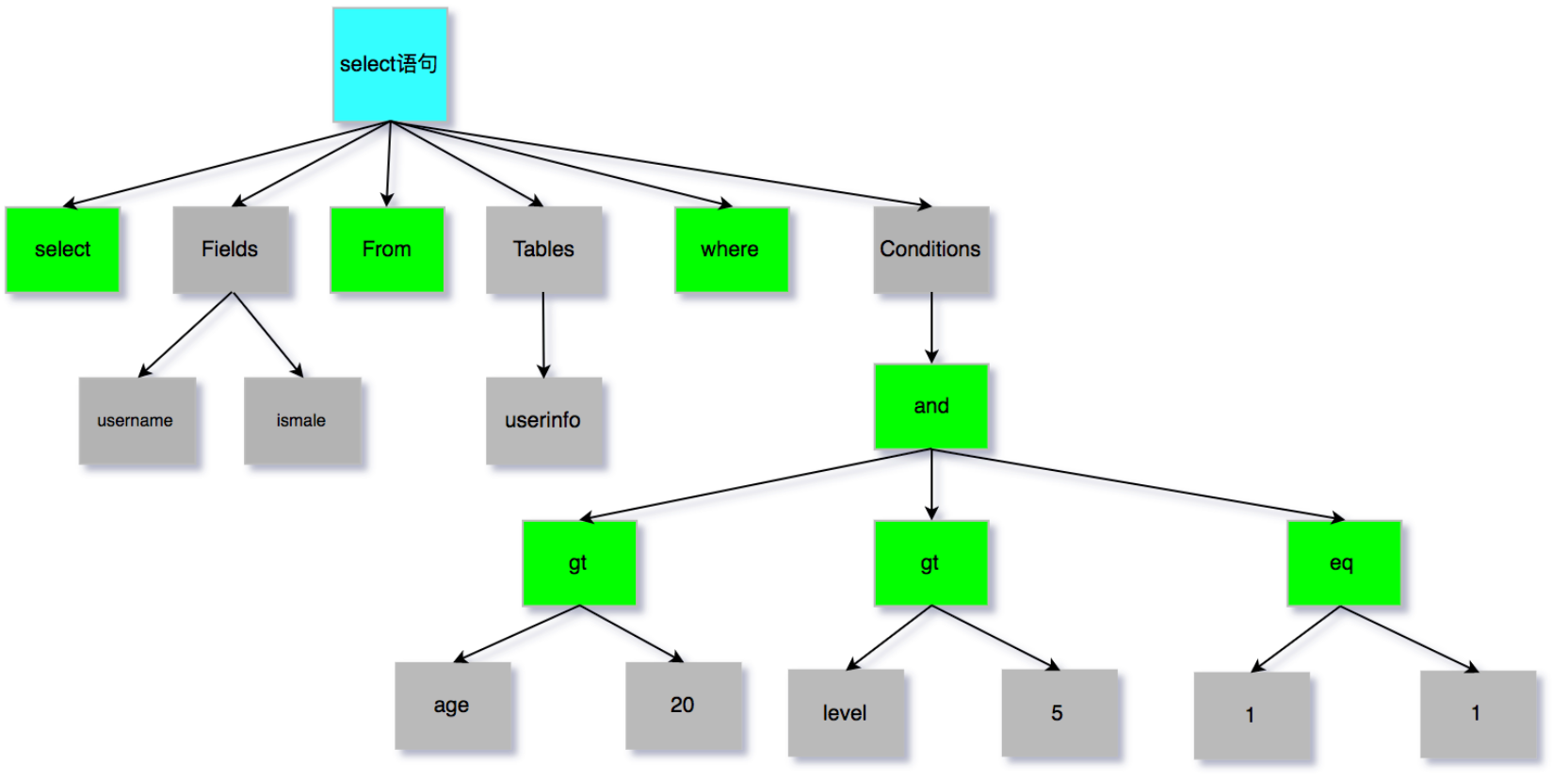
从上面的语法上树不难看出原sql语句,这就是sql分析阶段,当这一步完成以后,就会进入预处理阶段
四.预处理器
根据一些mysql规则进一步检查解析树是否合法。如检查查询的表名、列名是否正确,是否有表的权限
这一步操作目的是解决原来每一句sql都会单独解析执行的问题,后来变成了使用预处理器,对于相同的命令模板,不断的替换参数,减少对表权限和语法树是否合法的计算
生成命令模板:对于第一次进入的sql语句肯定是没有命令模板的,所以它需要参与生成命令模板 ,比如select id from student where id =1; 那么 “ select id from student where id = ” 就会成为模板
当模板生成了以后,对于student这个表,属性为id的字段,这个模板是已经检查过有没有权限的了,它在这个模板上都是有记录的
替换参数条件:这是对于有模板的情况下,我们就会直接使用参数替换的形式,把命令完成,比如这个时候有一条sql:select id from student where id = 100 ;很显然,上次我们已经生成过模板了,
就可以直接用,模板就是select id from student where id = 这个时候就只需要把参数替换掉,这次 id = 100;就把原来的 1 替换为100 ,这样做的好处就是,不用再去检查语法树合不合法了,
不用去看表是否有没有权限了,因为在生成模板的时候这些操作都是做过的了,如果模板语法树不合法,拿这次的sql也不合法,如果模板没有student表的权限,那么这次也没有
极大避免了二次计算和操作,对性能的提升非常大
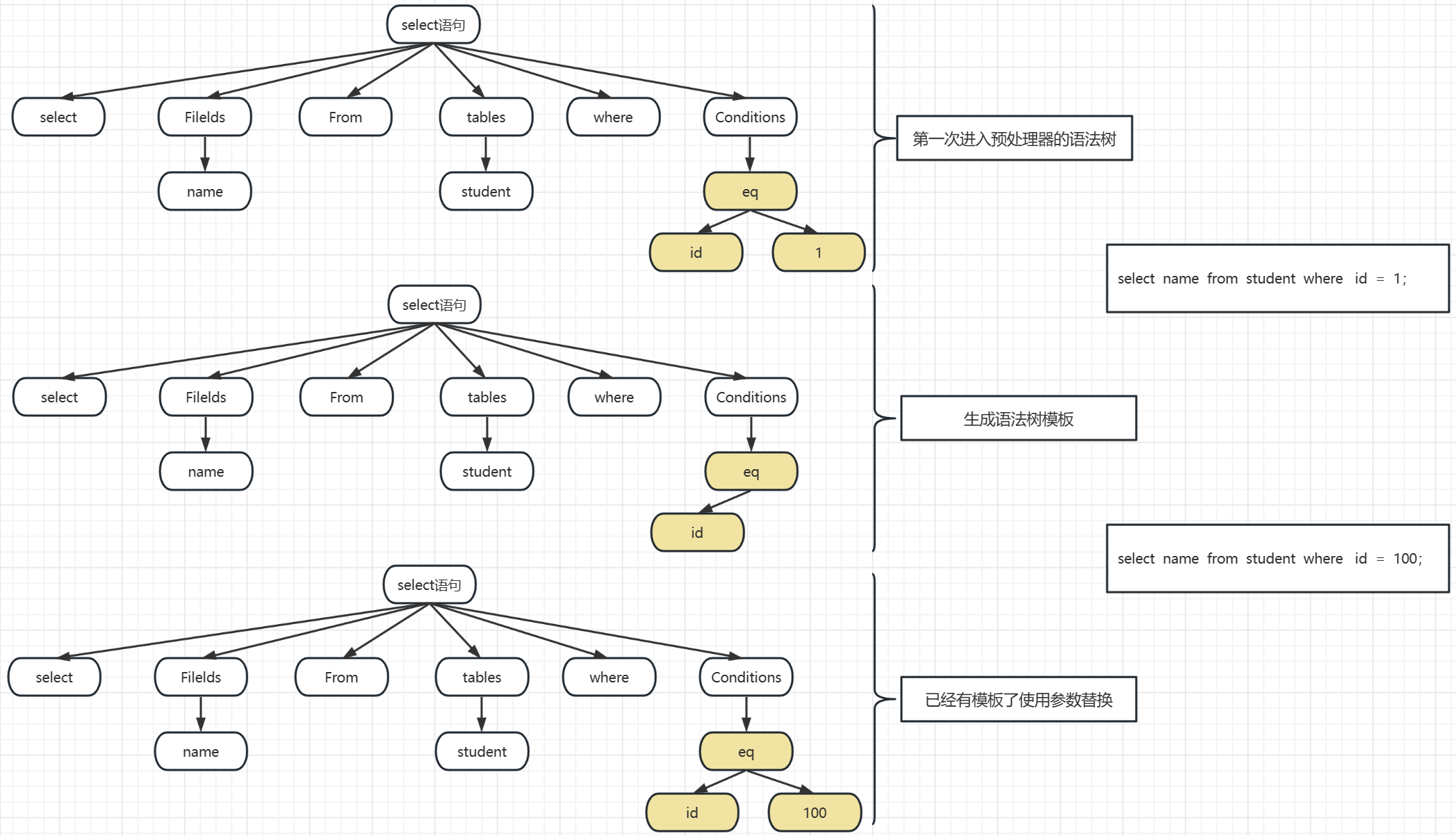
经过了预处理器以后,就拿到了这句sql是否有执行的权力,即能否更改表和查询表的权力,
如果权限没有问题,那么就可以进行下一步:SQL优化
五.SQL优化器
当语法树被认为是合法的了,并且由优化器将其转化成执行计划。一条查询可以有很多种执行方式,最后都返回相同的结果。优化器的作用就是找到这其中最好的执行计划。
执行计划:mysql不会生成查询字节码来执行查询,mysql生成查询的一棵指令树,然后通过存储引擎执行完成这棵指令树并返回结果。最终的执行计划包含了重构查询的全部信息。
查询的生命周期的下一步是将一个SQL转换成一个执行计划,mysql在依照这个执行计划和存储引擎进行交互。这包含多个子阶段:解析SQL、预处理、优化SQL执行计划。这个过程中任何错误都可能终止查询。
- 查询优化器:当语法树被认为是合法的了,并且由优化器将其转化成执行计划。一条查询可以有很多种执行方式,最后都返回相同的结果。优化器的作用就是找到这其中最好的执行计划。
- 执行计划:mysql不会生成查询字节码来执行查询,mysql生成查询的一棵指令树,然后通过存储引擎执行完成这棵指令树并返回结果。最终的执行计划包含了重构查询的全部信息。
在优化器的内部,是开发者定义的许多“优化规则”来进行优化的,如关联查询重排,索引优选,连接查询重组,优化排序,优化聚合函数,提前终止查询,等价变化等;
这里我们简单来列举一下索引优选:
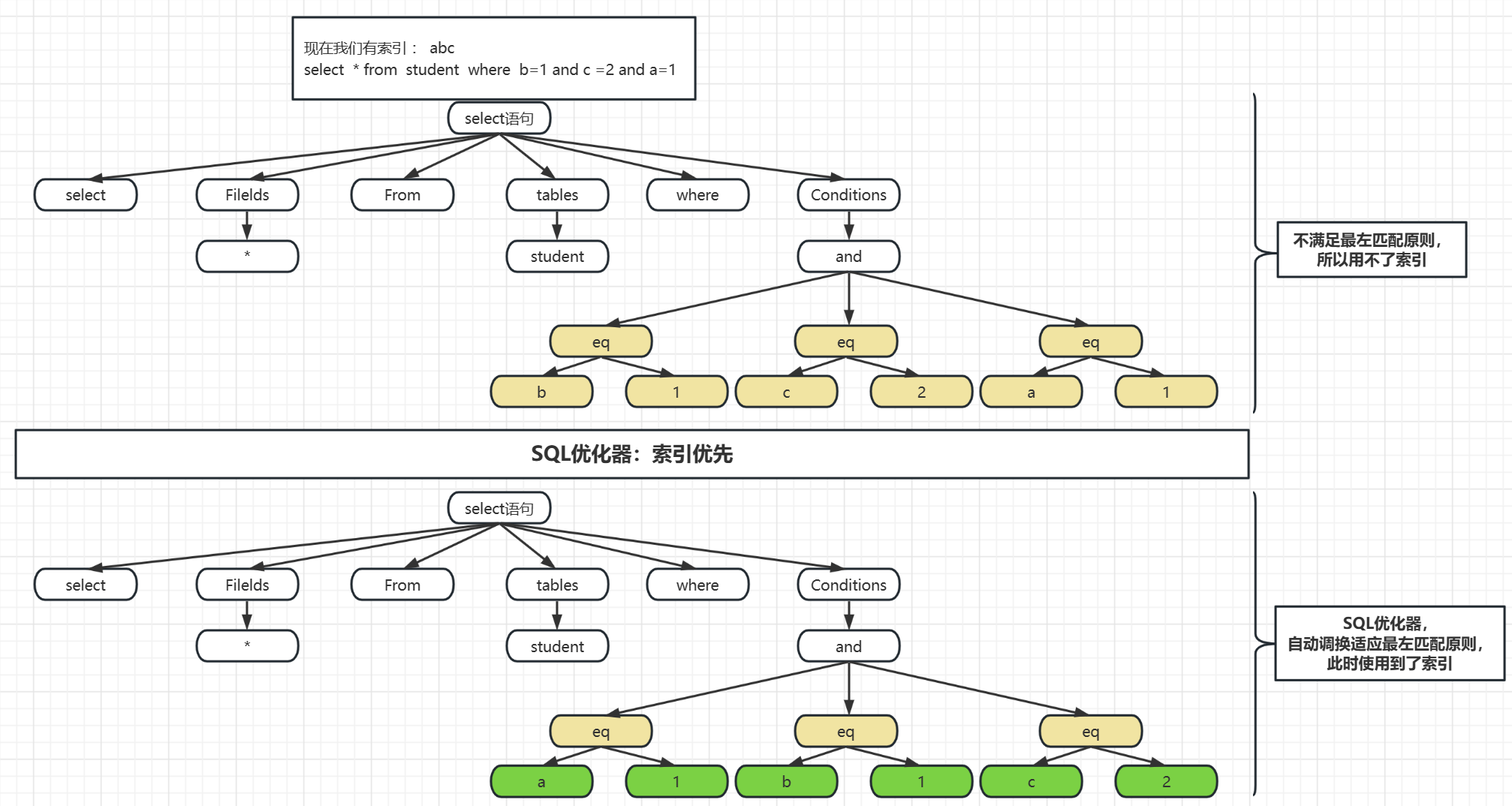
这个简单的例子应该可以感受到SQL优化器的作用是干什么的了,它内置很多规则,它贴合物理层,有自己的执行规则,同时又因为一些不合格的程序员写的sql不合规
这就导致SQL优化器非常重要了,能到sql优化器处理的sql基本上语法都是没问题的,主要的是怎么提高sql的执行效率,这就是优化器最大的作用
只要SQL优化器处理完了以后,就会生成执行计划,这个执行计划就是存储引擎的处理单元
生成执行计划以后,他就会交给执行器,去调用存储存储引擎的相应Headler API来完成相应的执行计划
六.执行器
这里的执行器和操作系统的操作系统差不多,都是负责调用和分发的,在sql执行中,执行器扮演两个角色
- 调用存储引擎的Headler API 处理执行计划
- 接收存储引擎返回的结果,并将它返回给服务器端
七.存储引擎(InnoDB)
我们常说的索引查询,遍历查询,临时表查询等等行为都是在存储引擎中完成的
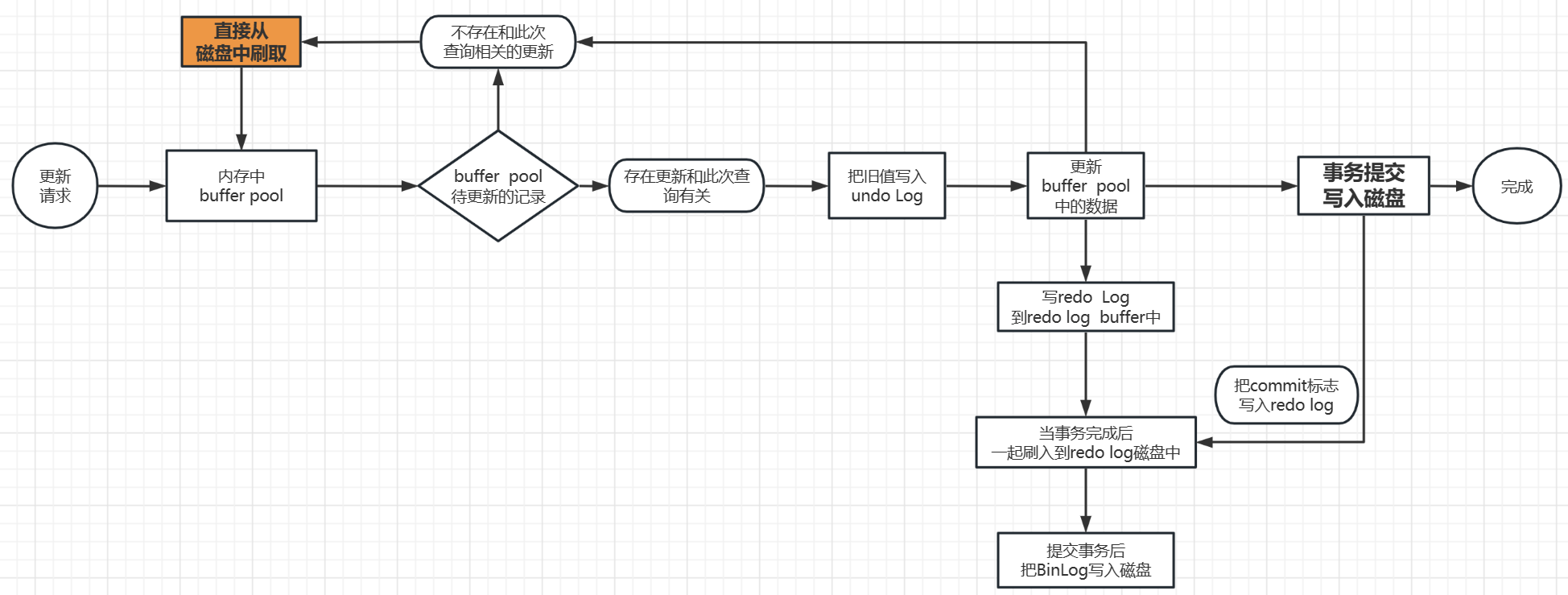
在我前面写的MySQL之存储引擎中有写道InnoDB是如何存储数据的,主要是内存的读写速度比硬盘的快,所以有了Buffer Pool ,这里当一个查询计划来了以后,他首先会去Buffer Pool中查看是否有关这次查询的相关更新,
如果没有,我们就会直接去磁盘中刷出数据到Buffer Pool中,然后由存储引擎负责返回给MySQL执行器,最后返回给服务器端
当Buffer Pool中有关此次查询的更新时,我们需要等到存储引擎把旧的值放到undo Log(用于事务回滚的日志)中,然后就会更新Buffer Pool和把更新数据刷入到磁盘,此时就可以去根据查询条件,查询数据到Buffer Pool中,
然后返回给MySQL执行器
有关InnoDB的存储,可以去看看我以前写的博客MySQL存储之InnoDB
拓展:什么是MySQL的二阶段提交?
MySQL的二阶段提交指的是MySQL为了保证redo Log和 Binlog的一致性而产生的一种设计,把日志写入和日志提交拆分成两个阶段,保证数据写入的一致性
redo log是事务日志,Binlog是数据变更的逻辑日志,二者必须同时成功,保证记录一致,
二阶段提交指的就是:
第一阶段:在事务开始时,MySQL会把操作记录到redo log中,同时会在redo log中打上 prepare 的标志,表示在redo log中事务开始了
第二阶段:在事务完成以后,会先记录到BinLog中,然后再去redo log中标记上commit,这样就保证了redo log 和binLog的一致性
以上就是MySQL的二次提交,所以InnoDB在写入redo log并不是一次写完的,而是分成两个阶段 prepare 和 commit
对应情况:
在写入 redo log 时崩溃:两个日志中都没有数据,满足数据的一致性
在写入redo log的prepare时崩溃:由于没有打上commit 的标记,所以在Binlog中找不到对应的这个事务的id,那么就需要执行回滚操作
在写入Binlog之后崩溃:由于redo log中的事务id可以在Bin log 中可以找到(表示事务已经刷入磁盘),所以可以直接提交数据,为redo log中事务打上commit标记