环境准备
为了能够按照教程顺利操作,需要注意几点细节
开始啦!
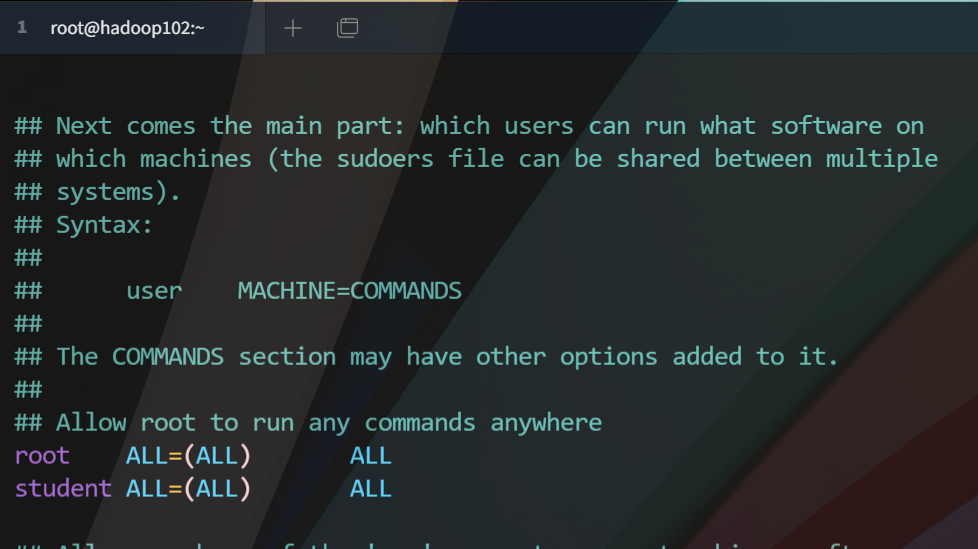
[root@hadoop102 ~]# useradd hadoop[root@hadoop102 ~]# passwd hadoop[root@hadoop102 ~]# vim /etc/sudoers? 将文件此处修改为这样(在100行左右)
[root@hadoop102 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33? 静态ip文件修改如下
TYPE="Ethernet"PROXY_METHOD="none"BROWSER_ONLY="no"BOOTPROTO="static"DEFROUTE="yes"IPV4_FAILURE_FATAL="no"IPV6INIT="yes"IPV6_AUTOCONF="yes"IPV6_DEFROUTE="yes"IPV6_FAILURE_FATAL="no"IPV6_ADDR_GEN_MODE="stable-privacy"NAME="ens33"UUID="385ea190-1b85-42cf-9df4-916f2dd86bc7"DEVICE="ens33"ONBOOT="yes"#ip 写自己设置的IPADDR=192.168.127.112#子网掩码 固定的NETMASK=255.255.255.0#网关 就是将你ip最后一段改成1GATEWAY=192.168.127.1[root@hadoop102 ~]# vim /etc/hostname? 文件内写入自己的主机名字即可
[root@hadoop102 ~]# vim /etc/hosts? hosts文件内容如下

关闭防火墙(运行b即可永久关闭)
一次性关闭 -- 重启之后系统会默认打开防火墙
[root@hadoop102 ~]# systemctl stop firewalld永久关闭防火墙
[root@hadoop102 ~]# systemctl disable firewalld查看当前防火墙状态
[root@hadoop102 ~]# systemctl status firewalld状态截图
重启机器,生效所有配置,注意 下次登录直接使用 hadoop 账户信息登录系统,这样子直接创建目录权限就是属于hadoop的
[root@hadoop102 ~]# reboot创建javajdk 和 hadoop 安装所需目录
创建软件安装包存放目录
[hadoop@hadoop102 /]$ sudo mkdir /opt/software[hadoop@hadoop102 /]$ sudo mkdir /opt/module赋予software目录上传权限,可以看到下面的权限已经允许外部读取写入
[root@hadoop102 opt]# chmod +777 /opt/software /opt/module[root@hadoop102 opt]# ll总用量 12drwxrwxrwx. 2 root root 4096 3月 9 21:56 moduledrwxr-xr-x. 2 root root 4096 10月 31 2018 rhdrwxrwxrwx. 2 root root 4096 3月 9 21:56 software上传hadoop和java安装包(本操作不涵盖,注意:使用任意的ftp工具登录连接时候请使用 hadoop 用户登录操作)
解压至module目录
[hadoop@hadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C ../module/[hadoop@hadoop102 software]$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C ../module/配置java 和 hadoop的环境变量
切换至root用户操作系统文件,操作完成之后切换成hadoop用户
[hadoop@hadoop102 software]$ su root使用root用户修改环境变量文件,在文件末尾追加如下信息,如果你的安装路径跟我不同这里需要写你自己的,跟着教程走且是同一个版本安装包或者同一个安装文件夹名字的不需要任何修改
#javaexport JAVA_HOME=/opt/module/jdk1.8.0_212export PATH=$PATH:$JAVA_HOME/bin#hadoop3.1.3export HADOOP_HOME=/opt/module/hadoop-3.1.3export PATH=$PATH:$HADOOP_HOME/bin切换至hadoop用户,并生效配置文件,查看效果
[hadoop@hadoop102 software]$ source /etc/profile自行运行如下命令进行环境测试,足够自行不测试也可以的。
[hadoop@hadoop102 software]$ java[hadoop@hadoop102 software]$ javac[hadoop@hadoop102 software]$ java -version[hadoop@hadoop102 software]$ hadoop version配置hadoop
编辑core-site.xml文件
[hadoop@hadoop102 /]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml<!-- 指定NameNode的地址 --><property> <name>fs.defaultFS</name> <value>hdfs://hadoop102:8020</value></property><!-- 指定hadoop数据的存储目录 --><property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-3.1.3/data</value></property>编辑hdfs-site.xml文件
[hadoop@hadoop102 /]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml<!-- nn web端访问地址--><property> <name>dfs.namenode.http-address</name> <value>hadoop102:9870</value></property><!-- 2nn web端访问地址--><property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop104:9868</value></property>编辑yarn-site.xml文件
[hadoop@hadoop102 /]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml<!-- 指定MR走shuffle --><property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value></property><!-- 指定ResourceManager的地址--><property> <name>yarn.resourcemanager.hostname</name> <value>hadoop103</value></property><!-- 环境变量的继承 --><property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property>编辑mapred-site.xml文件
[hadoop@hadoop102 /]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/mapred-site.xml<!-- 指定MapReduce程序运行在Yarn上 --><property> <name>mapreduce.framework.name</name> <value>yarn</value></property>编辑hadoop-env.sh文件
[hadoop@hadoop102 /]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/hadoop-env.shexport JAVA_HOME=/opt/module/jdk1.8.0_212编辑workers文件
[hadoop@hadoop102 hadoop]$ vim workershadoop102hadoop103hadoop104到此步骤,关闭虚拟机,克隆两台,请自行百度,待克隆完成之后,开启两个克隆的机器,不要通过终端连接,然后做下面操作,在vm中进行。
三台主机都使用root用户登录
修改克隆1机器的主机名
[root@hadoop102 hadoop]# vim /etc/hostname内容如下
hadoop103修改克隆1的ip
[root@hadoop102 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33 内容如下
TYPE="Ethernet"PROXY_METHOD="none"BROWSER_ONLY="no"BOOTPROTO="static"DEFROUTE="yes"IPV4_FAILURE_FATAL="no"IPV6INIT="yes"IPV6_AUTOCONF="yes"IPV6_DEFROUTE="yes"IPV6_FAILURE_FATAL="no"IPV6_ADDR_GEN_MODE="stable-privacy"NAME="ens33"UUID="385ea190-1b85-42cf-9df4-916f2dd86bc7"DEVICE="ens33"ONBOOT="yes"IPADDR=192.168.127.113NETMASK=255.255.255.0GATEWAY=192.168.127.1修改克隆2机器的主机名
[root@hadoop102 hadoop]# vim /etc/hostname内容如下
hadoop104修改克隆2机器的ip
[root@hadoop102 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33 内容如下
TYPE="Ethernet"PROXY_METHOD="none"BROWSER_ONLY="no"BOOTPROTO="static"DEFROUTE="yes"IPV4_FAILURE_FATAL="no"IPV6INIT="yes"IPV6_AUTOCONF="yes"IPV6_DEFROUTE="yes"IPV6_FAILURE_FATAL="no"IPV6_ADDR_GEN_MODE="stable-privacy"NAME="ens33"UUID="385ea190-1b85-42cf-9df4-916f2dd86bc7"DEVICE="ens33"ONBOOT="yes"IPADDR=192.168.127.114NETMASK=255.255.255.0GATEWAY=192.168.127.1重启两台克隆机器,使配置重新加载生效。
[root@hadoop102 ~]#reboot配置免密登录
hadoop102生成免密并发送给其余两个节点(hadoop102,hadoop103,hadoop104)
[hadoop@hadoop102 .ssh]$ ssh-keygen -t rsa[hadoop@hadoop104 .ssh]$ ssh-copy-id hadoop102[hadoop@hadoop102 .ssh]$ ssh-copy-id hadoop103[hadoop@hadoop102 .ssh]$ ssh-copy-id hadoop104hadoop103生成免密并发送给其余两个节点(hadoop102,hadoop103,hadoop104)
[hadoop@hadoop103 .ssh]$ ssh-keygen -t rsa[hadoop@hadoop103 .ssh]$ ssh-copy-id hadoop102[hadoop@hadoop104 .ssh]$ ssh-copy-id hadoop103[hadoop@hadoop103 .ssh]$ ssh-copy-id hadoop104hadoop104生成免密并发送给其余两个节点(hadoop102,hadoop104,hadoop103)
[hadoop@hadoop104 .ssh]$ ssh-keygen -t rsa[hadoop@hadoop104 .ssh]$ ssh-copy-id hadoop102[hadoop@hadoop104 .ssh]$ ssh-copy-id hadoop103[hadoop@hadoop104 .ssh]$ ssh-copy-id hadoop104格式化(必须主节点操作,既hadoop102这个节点)
[hadoop@hadoop102 sbin]$ hdfs namenode -format然后可以通过如下文本查看对应的信息
192.168.127.112:9870 --访问hadoop集群前台页面192.168.127.113:8088 --访问hadoop的所有应用页面还可以通过各个节点jps命令查看启动的任务节点状态。本文来自博客园,作者:刘盛哲的学习笔记,转载请注明原文链接:https://www.cnblogs.com/lszbk/p/15987604.html
