该博文放在javaWeb系列下,目的是记录我们javaWeb阶段所学的知识 @time=2022/3/11/11:52(最近休息玩了两天,今天重新启动生活)
官网:https://mybatis.org/mybatis-3/zh/index.html
MyBatis本是apache的一个开源项目iBatis,2010年这个项目由apache software foundation迁移到了[google code](https://baike.baidu.com/item/google code/2346604),并且改名为MyBatis。2013年11月迁移到Github。
iBATIS一词来源于“internet”和“abatis”的组合,是一个基于Java的持久层框架。iBATIS提供的持久层框架包括SQL Maps和Data Access Objects(DAOs)。
? ----百度百科
正是因为mybatis的前身是ibatis,所以在idea下import库的时候都是 import org.apache.ibatis.*等文件
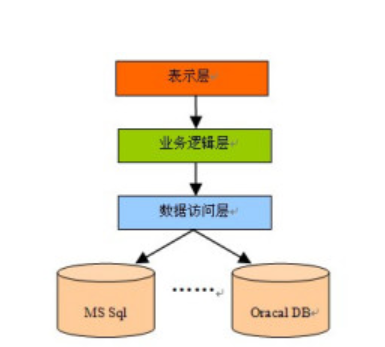
分层式设计是最常见也是最重要的一种结构,微软推荐的分层结构一般分为三层,从下至上分别为:数据访问层(DAO层),服务逻辑层(service层),表现层(action层),三层架构和MVC架构设计是不同的,目前我个人做的东西少,还没有体会出来这二者有什么区别。
代码分层是为了让代码结构更加清楚,还可以使项目分工更加明确,可读性大大提升,更加有利于后期的维护和升级,另外一个很重要的作用是降低耦合度,代码后期修改更加方便。
引出一个问题,关于异常在这些层中抛出的问题,也就是每个层得到的异常究竟应该如何抛出,例如我们底层DAO层遇到的大多是数据库操作的异常,对于这些异常,我们通常使用捕获抛出,try{}catch(SQLException e){throw new Exception(e.message())},在表示层我们捕获之后,使用不同的页面来提示用户错误,而不应该直接让用户看见DAO层的访问错误。
硬编码(英语:Hard Code 或 Hard Coding )是指在软件实现上,将输出或输入的相关参数(例如:路径、输出的形式或格式)直接以常量的方式撰写在源代码中,而非在运行期间由外界指定的设置、资源、数据或格式做出适当回应。一般被认定是种反模式或不完美的实现。
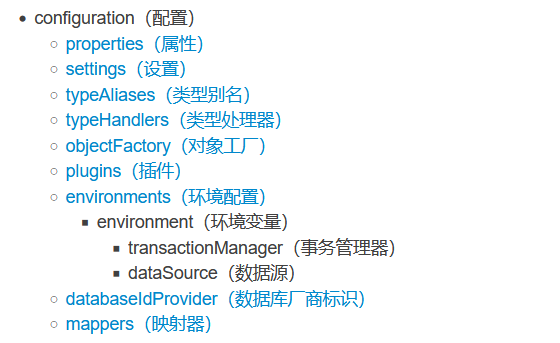
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"><configuration> <!--解释点1:--> <!--这个setting开启将sql中有下划线的名字映射为驼峰命名法命名的类属性,Camel的意思是驼峰命名法--> <settings> <setting name="mapUnderscoreToCamelCase" value="true"/> <setting name="logImpl" value="JDK_LOGGING"/> </settings> <!--下面这个是扫描一个包中的类。给包中的所有类都起别名,别名是类名的首字母小写(java规定所有的类名字都要大写)--> <typeAliases> <package name="mybatis.entity"/> </typeAliases> <!--alias起别名,给自己常用的类起别名,在mapper中就可以直接使用别名了,这是单独的写法--><!-- <typeAliases >--><!-- <typeAlias type="mybatis.entity.User" alias="lbwnb"/>--><!-- </typeAliases>--> <!--解释点2--> <!--enviroments设置的开发环境,目前是开发环境development,我们可以定义另外一个环境--> <environments default="development"> <environment id="development"> <!--事务管理器--> <transactionManager type="JDBC"> <!--中间可以写properties属性,但是这里使用的是默认的jdbc--> </transactionManager> <!--数据源,pooled池化--> <dataSource type="POOLED"> <!--读取配置自动连接--> <property name="driver" value="com.mysql.cj.jdbc.Driver"/> <!--&等于&--> <property name="url" value="jdbc:mysql://localhost:3306/school?&useSSL=false"/> <property name="username" value="root"/> <property name="password" value="011013"/> </dataSource> </environment> <!--另外一套环境是start,虽然这里配置是这样的,但是我们可以在创建sqlsessionfactory的时候,我们给传进去第二个参数,可以指定环境--> <environment id="start"> <transactionManager type="JDBC"/> <dataSource type="POOLED"> <!--读取配置自动连接--> <property name="driver" value="com.mysql.cj.jdbc.Driver"/> <!--&等于&--> <property name="url" value="jdbc:mysql://localhost:3306/school?&useSSL=false"/> <property name="username" value="root"/> <property name="password" value="011013"/> </dataSource> </environment> </environments> <!--解释点3--> <mappers> <!--但是值得注意的是不能重复注册--> <!--mapper映射的多种细节详细去见官网说明:class是通过将 单个 的映射器接口注册为,后续就会使用register去实现--><!-- <mapper ></mapper>--> <!--package是将一个包内所有的接口都给注册--> <package name="mybatis.mapper"/> </mappers></configuration>在xml配置文件中,标签对的顺序必须按照:
的顺序进行,否则会提示报错。
解释点1:关于xml配置文件中setting的设置等信息(挑选几个重要的)
| 设置名 | 描述 | 取值 | 默认值 |
|---|---|---|---|
| cacheEnabled | 全局性的开启或者关闭所有映射器配置文件中已经配置的任何缓存 | true/false | false |
| logImpl | mybatis的日志是否开启 | JDK_LOGGING ,LOG4J等 | 无 |
| mapUnderscoreToCamelCase | 对于数据库的下换线字段名是否映射为驼峰命名法 | true/false | false |
解释点2:关于environment的解释
MyBatis 可以配置成适应多种环境,这种机制有助于将 SQL 映射应用于多种数据库之中,现实情况下有多种理由需要这么做。例如,开发、测试和生产环境需要有不同的配置;或者想在具有相同 Schema 的多个生产数据库中使用相同的 SQL 映射。还有许多类似的使用场景。
不过我们需要记住的,每个sqlsessionfactory只能对应一个环境,也就是说,两个环境就要使用两个sqlsessionfactory。 每个数据库对应一个 SqlSessionFactory 实例
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader, environment);SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(reader, environment, properties);解释点3:查找映射器

我当时学习对于完全限定资源定位符产生了很大的疑惑,目前我个人反正很难使用file这个url通过相对路径找到xml配置文件,不喜欢用
注意在xml中的类名如果要直接使用需要提前在config文件中配置别名属性,我们之后才可以直接使用类名而不是使用包名
select语句
<select id='selectStu' parameterType='int' resultType='Stu'> select * from stu where stu.id=#{id}/*这里没有写分号*/ </select>id这里是为查询语句起的名字,之后有两种使用方式 一种是定义对于接口命名的时候起的接口函数名字是这个id,将二者绑定,另外一种方式是,在sqlsession直接使用方法
parameterType是指定下面参数的类型,不建议填写,根据动态传入的参数类型作为判定
resultType是返回值的实体类型
预编译参数两种写法:#{}和${} #{}是使用PreparedStatement进行预编译,可以有效防止sql注入,${}是使用Statement进行处理
insert语句
<!--插入操作--> <insert id="addUser"> insert into user values(#{username},#{pw}) </insert>delete语句
<delete id="deleteUser"> /*建议在这里写预编译的参数的时候,名称都和你后面要传的实体类中的属性名相同,不然无法完成对应,通过属性名称来传递过去*/ delete from user where username = #{username}; </delete>update
<update id="??"> update xxx set xxx.id=1 where xxx.id = #{} </update>这里除了select其他的几个语句返回值都是int代表affect rows
强大的resultMap
在实际情况中,我们可能会遇到复杂的查询,例如:
SELECT * from stu inner join teach on(teach.sid =stu.sid) inner join teacher on (teacher.tid=teach.tid) where teacher.tid = #{tid}这样产生的一个teacher类中,含有集合类类型Stus,我们通过普通的映射,无法将结果集映射为一个实体类,我们需要通过resultMap来保证映射过程的正确性:
<resultMap id="reM1" type="teacher"> <!--子元素id代表resultMap的主键,而result代表其属性。也就是显性的标注出主键,那么这里我们其实也可以使用result,id有用,尤其是应用到缓存和内嵌的结果映射--> <!--id标签用于在多条件记录中辨别是否为同一个对象的数据,查询语句得到的结果中,tid相同的鉴别为同一个对象的数据,这样下面的collection才会生效--> <id column="tid" property="tid"/> <result column="tname" property="tname"/> <!--让collection指向我们需要一对多的类型,这里是stu,然后将我们的属性指向它,oftype好像是在集合中用的--> <collection property="Students" ofType="stu"> <id property="sid" column="sid"/> <result column="sname" property="sname"/> </collection> </resultMap>通过配置resultMap,另外在select查询中指定出匹配的map,就可以实现具体的功能。
<select id='select1' resultMap='reM1' resultType='Teacher'> SELECT * from stu inner join teach on(teach.sid =stu.sid) inner join teacher on (teacher.tid=teach.tid) where teacher.tid = #{tid}</select>下面是resultMap标签中的所有可以选择的标签值,这里我只使用过其中的一部分

具体讲解可以查看官网的介绍https://mybatis.org/mybatis-3/zh/sqlmap-xml.html
我只说几个我能用到的:
constructor构造
将我们结果集中的数据通过指定的方式注入到实体类的相应的构造方法中去(@DATA注解生成的JavaBean只有默认的构造方式)
对于构造方法:
public class User { //... public User(Integer id, String username, int age) { //... }//...}可以使用构造标签
<constructor> <idArg column="id" javaType="int"/> <arg column="username" javaType="String"/> <arg column="age" javaType="_int"/>/*这里int包装类和基本类intjavaType是不一样的*/</constructor>这里是按照默认的顺序去传递参数到构造方法中,(也就是并不会按照结果集的名字和匹配)
如果我们想要把结果集的id传给实体类的age,可以这样
<constructor> <idArg column="id" javaType="int" name="age" /> <arg column="age" javaType="_int" name="id" /> <arg column="username" javaType="String" name="username" />/*name参数是实体类的属性*/</constructor>collection和上面演示的相同,是在一对多的时候,表示如何将多个对象映射成为集合类,存储在一个实体类中
association代表多对一的映射,表明如何将一个对象(例如教师)映映射给许多的学生中去
缓存cache
? MyBatis 内置了一个强大的事务性查询缓存机制,它可以非常方便地配置和定制。为了使它更加强大而且易于配置,我们对 MyBatis 3 中的缓存实现进行了许多改进。
? 默认情况下,只启用了本地的会话缓存,它仅仅对一个会话中的数据进行缓存。要启用全局的二级缓存,需要在SQL映射中添加一句
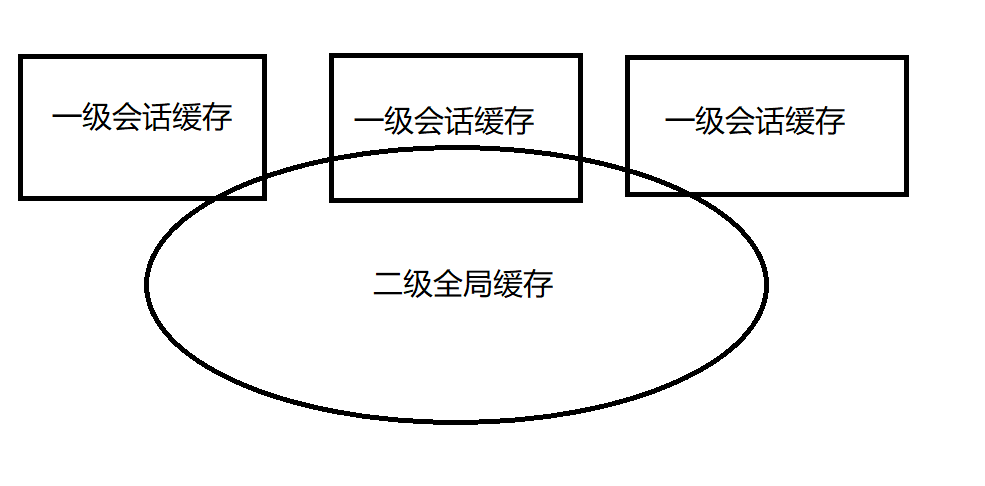
默认情况下,mybatis只开启了一级缓存,例如下面的例子
try(SqlSession sqlSession1=MybatisUnits.getSqlSession(true)) { UnionSearch mapper1 = sqlSession1.getMapper(UnionSearch.class); t1 = mapper1.getTeacherById("1"); t2=mapper1.getTeacherById("1"); System.out.println(t1==t2);//判断地址是否相同,得到true,在同一个会话下,我们得到的数据是被缓存的 }验证是否开启二级缓存:
Teacher t1,t2; try(SqlSession sqlSession1=MybatisUnits.getSqlSession(true)) { UnionSearch mapper1 = sqlSession1.getMapper(UnionSearch.class); t1 = mapper1.getTeacherById("1"); } try(SqlSession sqlSession2=MybatisUnits.getSqlSession(true)) { UnionSearch mapper2 = sqlSession2.getMapper(UnionSearch.class); t2 = mapper2.getTeacherById("1"); }System.out.println(t1==t2);//得到false,知道二级缓存是关闭的开启二级缓存需要在mapper.xml文件下填写相应的内容:
<cache eviction="FIFO" flushInterval="6000" size="512" readOnly="true"/>eviction:清除缓存的规则,有下面的几个数值:
LRU – 最近最少使用:移除最长时间不被使用的对象。
FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
SOFT – 软引用:基于垃圾回收器状态和软引用规则移除对象。
WEAK – 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
flushInterval:间隔多长时间刷新一次,单位是毫秒
size是缓存的大小,单位是(官网没说,我个人觉得是mb),默认是1024
readOnly:设置是否只读,默认false,设置为true会在多线程下更加安全,但是速度会更加的慢
官网文档:https://mybatis.org/mybatis-3/zh/dynamic-sql.html
没有用过,说不出来啥,个人理解是为了方便动态的拼接SQL使用的,中间可以添加我们传入参数的判断。
https://mybatis.org/mybatis-3/zh/logging.html,可以使用配置文件设置,只用过标准输出日志和文件输出的日志。
反倒是lombok的日志常用点。
https://www.cnblogs.com/sword-successful/p/10164864.html,我自己对于代理模式搞的不是特别清楚。
mybatis支持映射的方式有三种(我自己知道的)
下面我们来说一下使用注解配合接口开发
查@Select
@Select("select * from stu where stu.id=#{id}")public stu getSutById(int id);ps:这里需要注意的是有了两个参数的的时候需要这样写
@Select("select * from stu wherr stu.name=#{name} and stu.sex=#{sex}")publci stu getStuByParameter(@Param('name') String name,@Param('sex') String sex);通过注解来指定上下文参数对应关系
增@insert
删@delete
改@update
以上三个我就不详细写了
@Results
对应xml文件中的ResultMap,下面我们写一个示例来演示上面说过的老师对应多个学生
@Options(useCache = false,flushCache = Options.FlushCachePolicy.TRUE) //使用注解来完成复杂查询 @Results(id = "reM1",{ @Result(id=true ,column = "tid",property = "tid"), @Result(column = "tname",property = "tname"), @Result(column = "tid",property = "Students",many = @Many( select = "getStuByTid" )) }) @Select("SELECT * from teacher where tid=#{tid}") Teacher getTeacherBO(String tid);这里记不住的,到时候使用可以在查找,记住@result中的几个属性就行了,分别是column对应的是结果集中的字段名,property是返回类中的属性名。
many=@Many{ select="方法名" }是一对多的使用,分别使用我们指定的 column='id'传入到getStuById中返回相应数据,组合称为Students这个属性。
我们还可以看见@Results(id = "reM1")这个id属性,我们同样可以在一个方法前加入注解:@ResultMap(id="reM1")来指定一个使用注解的ResultMap或者xml中的ResultMap。
@option
@option选项是加载一些可选项,例如打开缓存等等,使用的不多,我就不多叭叭了
优缺点:
使用接口注解的优点:
使用接口注解的缺点:
适用于比较简单的配置,当太复杂了接口就搞不定了。
不能使用动态SQL,有点鸡肋。