在求解n维线性系统 \(Ax=b\) ,我们通常将因子\(A\)分解为两个三角矩阵,即 \(A=LU\) :
从而使得求解 \(Ax=b\) ,变成了求解 \(L(Ux)=b\) :
直接求解 \(A\) 的复杂度为 \(O(n^3)\) ,但是求解三角系统的复杂度为 \(O(n^2)\) 。
由公式 \(Ly=b\) 展开可得:
求出对角元素:
由上面推到过程可得,对于 \(k=1,2,...,n\) :
伪代码算法实现:
for k from 1 to n do: y[k]=b[k]; for i from 1 to k-1 do: y[k]=y[k]-l[k][i]*y[i];反向替换过程类似
根据上文中的公式,可以很快写出C语言代码如下:
void solve_triangular_system_swapped( int n, double **L, double *b, double *y ){ for(int i=0;i<n;++i){ y[i]=b[i]; for(int j=0;j<i;++j){ y[i]=y[i]-y[j]*L[i][j]; } }}三种典型的Pipeline:
第三种Pipline,通常情况下每个指令长度不一。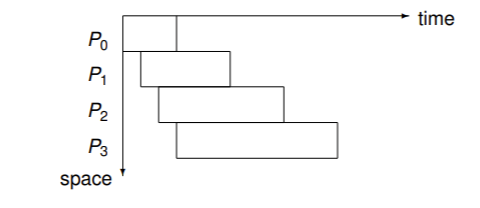
传统指令Pipeline
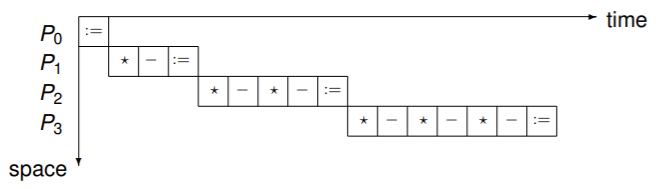
第三种Pipeline
使 \(y_1\) 在下一个流水中可用:
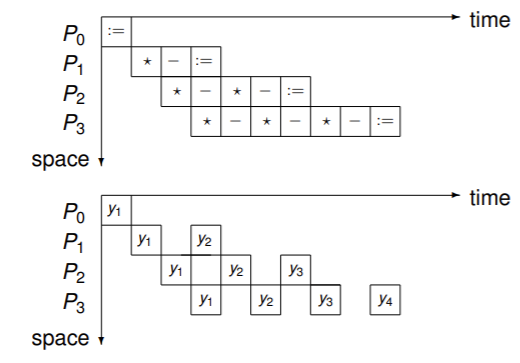
因此我们需要重写算法和公式
以 \(Ly=b\) 前五步为例:
\(y:=b\)
\(\begin{array}{l} y_2:=y_2-l_{2,1}*y_1;\\y_3:=y_3-l_{3,1}*y_1;\\y_4:=y_4-l_{4,1}*y_1;\\y_5:=y_5-l_{5,1}*y_1;\\\end{array}\)
\(\begin{array}{l} y_3:=y_3-l_{3,2}*y_2;\\y_4:=y_4-l_{4,2}*y_2;\\y_5:=y_5-l_{5,2}*y_2;\end{array}\)
\(\begin{array}{l} y_4:=y_4-l_{4,3}*y_3;\\y_5:=y_5-l_{5,3}*y_3;\end{array}\)
即:
y:=b;for i from 2 to n do for j from i to n do y_j=y_j-l[j,i-1]*y_{i-1};由伪代码可写C语言代码:
void solve_triangular_system_swapped( int n, double **L, double *b, double *y ){ for(int i=0; i<n; i++) y[i] = b[i]; for(int i=1; i<n; i++) { for(int j=i; j<n; j++) y[j] = y[j] - L[j][i-1]*y[i-1]; }}VC++编译优化参数为\Od
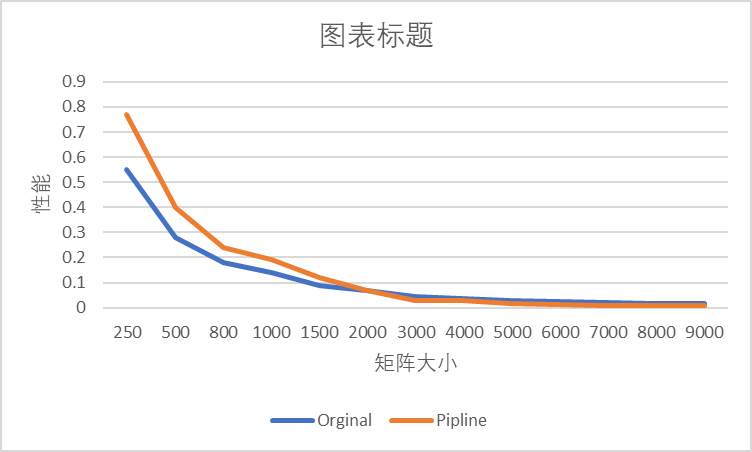
使用循环展开对程序的性能进行优化也是常用的手段。循环展开层数取决于CPU逻辑寄存器的数量。因为Pipline在处理大矩阵时,性能较差,其次在\O1 优化的情况下原始代码有着和Pipline优化后相仿的性能,因此这里只对原始代码进行Unroll。
int j = 0, i = 0; for (i = 0; i < n; ++i) { y[i] = b[i]; for (j = 0; j < i; j += 4) { y[i] = y[i] - y[j] * L[i][j]; y[i] = y[i] - y[j + 1] * L[i][j + 1]; y[i] = y[i] - y[j + 2] * L[i][j + 2]; y[i] = y[i] - y[j + 3] * L[i][j + 3]; } for (; j < i; j++) { y[i] = y[i] - y[j] * L[i][j]; } }VC++编译优化参数为\O1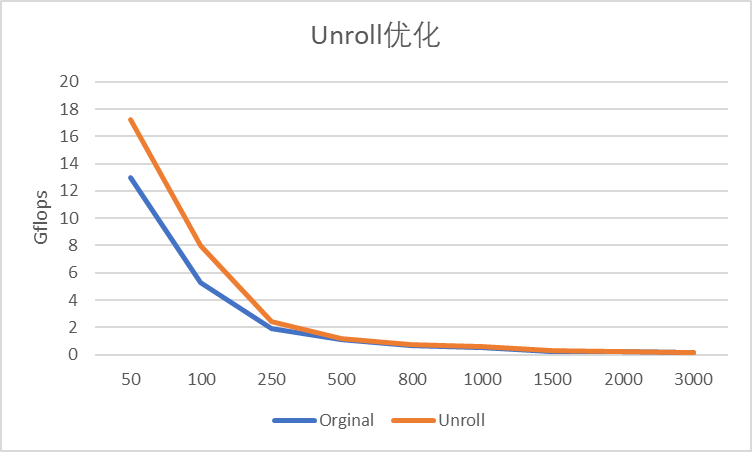
使用多个线程来提升性能:
void solve_triangular_system_swapped_omp( int n, double **L, double *b, double *y ){ for(int i=0; i<n; i++) y[i] = b[i]; for(int i=1; i<n; i++) { #pragma omp parallel shared(L,y) private(j) { #pragma omp for for(int j=i; j<n; j++) y[j] = y[j] - L[j][i-1]*y[i-1]; } }}