我们在使用缓存的时候都会不可避免的考虑到如何应对 缓存雪崩 , 缓存穿透 和 缓存击穿 ,这里我们就来讲讲如何解决缓存穿透。
缓存穿透是指当有人非法请求不存在的数据的时候,由于数据不存在,所以缓存不会生效,请求会直接打到数据库上,当大量请求集中在该不存在的数据上的时候,会导致数据库挂掉。
那么解决方法有好几个:
那么布隆过滤器是什么来的?
布隆过滤器( Bloom Filter )是1970年由布隆提出。主要用于判断一个元素是否在一个集合中。通过将元素转化成哈希函数再经过一系列的计算,最终得出多个下标,然后在长度为n的数组中该下标的值修改为1。
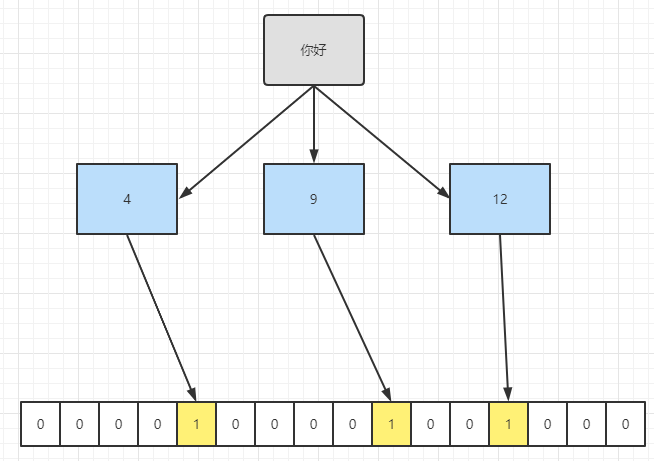
那么如何判断该元素是否在这一个集合中只需要判断计算得出的下标的值是否为1即可。
当然布隆过滤器也不是完美无缺的,其缺点就是存在误判,删除困难
| 优点 | 缺点 |
|---|---|
| 不需要存储key值,占用空间少 | 存在误判,不能100%判断元素存在 |
| 空间效率和查询时间远超一般算法 | 删除困难 |
布隆过滤器原理:当一个元素被加入集合时,通过 K 个散列函数将这个元素映射成一个位数组(Bit array)中的 K 个点,把它们置为 1 。检索时,只要看看这些点是不是都是1就知道元素是否在集合中;如果这些点有任何一个 0,则被检元素一定不在;如果都是1,则被检元素很可能在(之所以说“可能”是误差的存在)。
那么误差为什么存在呢?因为当存储量大的时候,哈希计算得出的下标有可能会相同,那么当两个元素得出的哈希下标相同时,就无法判断该元素是否一定存在了。
删除困难也是如此,因为下标有可能重复,当你对该下标的值归零的时候,有可能也会对其他元素造成影响。
那么应对缓存穿透,我们只需要在布隆过滤器上判断该元素是否存在,如果不存在则直接返回,如果判断存在则查询缓存和数据库,尽管有误判率的影响,但是也能够大大减少数据库的负担,同时也能够阻挡大部分的非法请求。
Redis有一系列位运算的命令,如 setbit , getbit 可以设置位数组的值,这个特性可以很好的实现布隆过滤器,有现成的依赖已经实现布隆过滤器了。
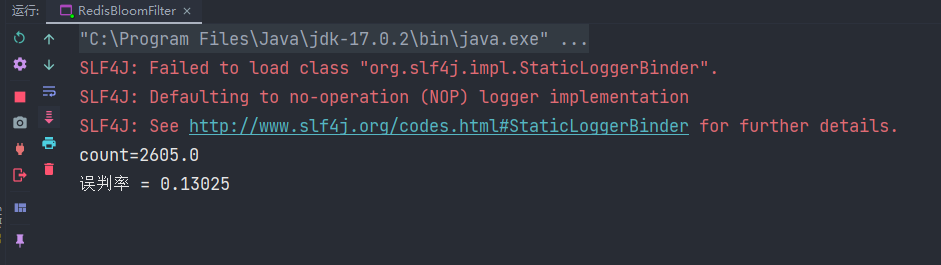
<dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.16.0</version></dependency>以下是测试代码,我们先填入8W的数字进去,然后再循环往后2W数字,测试其误判率
import org.redisson.Redisson;import org.redisson.api.RBloomFilter;import org.redisson.api.RedissonClient;import org.redisson.config.Config;public class RedisBloomFilter { public static void main(String[] args) { Config config = new Config(); config.useSingleServer().setAddress("redis://localhost:6379"); config.useSingleServer().setPassword("123456"); //创建redis连接 RedissonClient redissonClient = Redisson.create(config); //初始化布隆过滤器并传入该过滤器自定义命名 RBloomFilter<Integer> bloomFilter = redissonClient.getBloomFilter("BloomFilter"); //初始化布隆过滤器参数,设置元素数量和误判率 bloomFilter.tryInit(110000,0.1); //填充800W数字 for (int i = 0; i < 80000; i++) { bloomFilter.add(i); } //从8000001开始检查是否存在,测试误判率 double count = 0; for (int i = 80001; i < 100000; i++) { if (bloomFilter.contains(i)) { count++; } } // count / (1000000-8000001) 就可以得出误判率 System.out.println("count=" + count); System.out.println("误判率 = " + count / (100000 - 80001)); }}得出结论:在四舍五入下,误判率为0.1
添加Guava工具类依赖
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>30.1.1-jre</version></dependency>编写测试代码:
import com.google.common.base.Charsets;import com.google.common.hash.BloomFilter;import com.google.common.hash.Funnels;public class GuavaBloomFilter { public static void main(String[] args) { //初始化布隆过滤器 BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), 110000,0.1); //填充数据 for (int i = 0; i < 80000; i++) { bloomFilter.put(i); } //检测误判 double count = 0; for (int i = 80000; i < 100000; i++) { if (bloomFilter.mightContain(i)) { count++; } } System.out.println("count="+ count); System.out.println("误判率为" + count / (100000-80000)); }}结果:
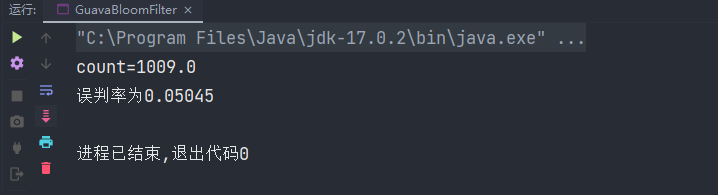
结果低于设置的误判率,我猜测可能是两者底层使用的hash算法不同导致的,而且在使用过程中可以明显得出使用Guava工具类的布隆过滤器速度是远远快于使用redisson,这可能是因为Guava是直接操作内存,而redisson要与Redis交互,在速度上肯定比不过直接操作内存的Guava。
我们使用Java一个封装好的位数组 BitSet 。BitSet 提供了大量API,基本的操作包括:
写一个布隆过滤器需要考虑的以下几点:
hash值得出高低位进行异或,然后乘以种子,再对位数组大小进行取余数。
import java.util.BitSet;public class MyBloomFilter { // 默认大小 private static final int DEFAULT_SIZE = Integer.MAX_VALUE; // 最小的大小 private static final int MIN_SIZE = 1000; // 大小为默认大小 private int SIZE = DEFAULT_SIZE; // hash函数的种子因子 private static final int[] HASH_SEEDS = new int[]{3, 5, 7, 11, 13, 17, 19, 23, 29, 31}; // 位数组,0/1,表示特征 private BitSet bitSet = null; // hash函数 private HashFunction[] hashFunctions = new HashFunction[HASH_SEEDS.length]; // 无参数初始化 public MyBloomFilter() { // 按照默认大小 init(); } // 带参数初始化 public MyBloomFilter(int size) { // 大小初始化小于最小的大小 if (size >= MIN_SIZE) { SIZE = size; } init(); } private void init() { // 初始化位大小 bitSet = new BitSet(SIZE); // 初始化hash函数 for (int i = 0; i < HASH_SEEDS.length; i++) { hashFunctions[i] = new HashFunction(SIZE, HASH_SEEDS[i]); } } // 添加元素,相当于把元素的特征添加到位数组 public void add(Object value) { for (HashFunction f : hashFunctions) { // 将hash计算出来的位置为true bitSet.set(f.hash(value), true); } } // 判断元素的特征是否存在于位数组 public boolean contains(Object value) { boolean result = true; for (HashFunction f : hashFunctions) { result = result && bitSet.get(f.hash(value)); // hash函数只要有一个计算出为false,则直接返回 if (!result) { return result; } } return result; } // hash函数 public static class HashFunction { // 位数组大小 private int size; // hash种子 private int seed; public HashFunction(int size, int seed) { this.size = size; this.seed = seed; } // hash函数 public int hash(Object value) { if (value == null) { return 0; } else { // hash值 int hash1 = value.hashCode(); // 高位的hash值 int hash2 = hash1 >>> 16; // 合并hash值(相当于把高低位的特征结合) int combine = hash1 ^ hash1; // 相乘再取余 return Math.abs(combine * seed) % size; } } } public static void main(String[] args) { Integer num1 = 12321; Integer num2 = 12345; MyBloomFilter myBloomFilter = new MyBloomFilter(); System.out.println(myBloomFilter.contains(num1)); System.out.println(myBloomFilter.contains(num2)); myBloomFilter.add(num1); myBloomFilter.add(num2); System.out.println(myBloomFilter.contains(num1)); System.out.println(myBloomFilter.contains(num2)); }}手写代码是来自 https://juejin.cn/post/6961681011423838221
通过代码可以得出实现一个简单的布隆过滤器需要一个位数组,多个哈希函数,以及对过滤添加元素和判断元素是否存在的方法。位数组空间越大,hash碰撞的概率就越小,所以布隆过滤器中误判率和空间大小是关联的,误判率越低,需要的空间就越大。
布隆过滤器的功能很明确,就是判断元素在集合中是否存在。有一些面试官可能会提问假如现在给你10W数据的集合,那么我要怎么快速确定某个数据在集合中是否存在,这个问题就可以使用布隆过滤器来解决,毕竟尽管布隆过滤器存在误判,但是可以100%确定该数据不存在,相较于其缺点,完全可以接受。
还有一些应用场景:
解决缓存穿透我们可以提前预热,将数据存入布隆过滤器中,请求进来后,先查询布隆过滤器是否存在该数据,假如数据不存在则直接返回,如果数据存在则先查询Redis,Redis不存在再查询数据库,假如有新的数据添加,也可以添加数据进布隆过滤器。当然如果有大量数据需要进行更新,那么最好就是重建布隆过滤器。
