梯度下降法是一种函数极值的优化算法。在机器学习中,主要用于寻找最小化损失函数的的最优解。是算法更新模型参数的常用的方法之一。
设一元函数\(f(x)\)在\(x_0\)的临域内有定义,若极限
\[f^{`}(x_0)=\lim_{\Delta x\to0}\frac{f(x+\Delta x)-f(x)}{\Delta }\]存在,则称\(f^{`}(x_0)\)为\(f(x)\)在\(x=x_0\)处的导数。
对于多元函数\(f(x),x \in R^p\),\(f(x)\)在对\(x_i\)的偏导数定义为
\[\frac{\partial f(x)}{\partial x_i}=\lim_{\Delta x \to 0}\frac{f(x_1,x_2,\cdots,x_i+\Delta x,\cdots,x_p)-f(x_1,x_2,\cdots,x_i,\cdots,x_p)}{\Delta x}\]
偏导数定义了多元函数在某个数轴方向上的变化情况。
函数的偏导数定义了在各个数轴上的变化率,方向导数则为函数在任意方向上的变化率。以二元函数\(f(x,y)\)为例:
\[\nabla \frac{\partial f(x)}{\partial l}|_{(x_0,y_0)}=\frac{\partial f(x)}{\partial x}\cos(\alpha)+\frac{\partial f(x)}{\partial y}\cos(\beta)\]
多元函数在某点处的方向导数有无数个,每一个方向导数的值代表了在该方向上的变化程度,我们要寻找在某点处函数变化最快的方向就可以转化成寻找在该点处方向导数的绝对值最大时对应的那个方向
梯度是一个矢量,表示函数沿着该方向的变化率最大,记为
\[f(x)=(\frac{\partial f(x)}{\partial x_1},\frac{\partial f(x)}{\partial x_2},\cdots,\frac{\partial f(x)}{\partial x_p})^T\]
根据方向导数定义,
\[\begin{align*}\frac{\partial f(x)}{\partial l}|_{(x_0,y_0)} &=\frac{\partial f(x)}{\partial x}\cos(\alpha)+\frac{\partial f(x)}{\partial y}\cos(\beta) \\&= (\frac{\partial f(x)}{\partial x},\frac{\partial f(x)}{\partial y})(\cos(\alpha),\cos(\beta))^T \\&= A\cdot I \quad\quad (A=(\frac{\partial f(x)}{\partial x},\frac{\partial f(x)}{\partial y}),I=(\cos(\alpha),\cos(\beta))^T ) \\&= ||A||\times||I||\cos(\theta) \qquad (\theta为两个向量的夹角)\end{align*}\]当且仅当 \(\theta=0\),即\(A\)和\(I\)通向时,方向导数取得最大值,因此梯度表示变化率最大的方向,此时方向导数为正。因此梯度指向函数增大的方向。
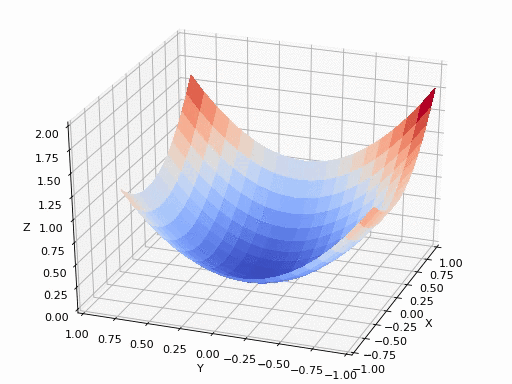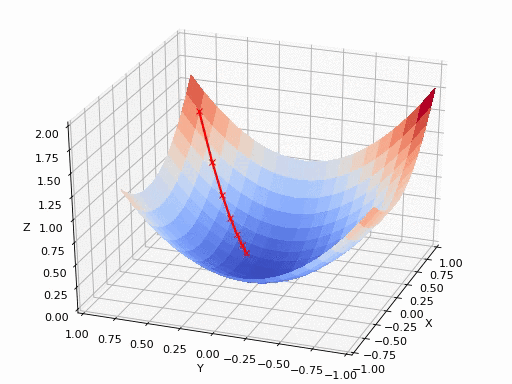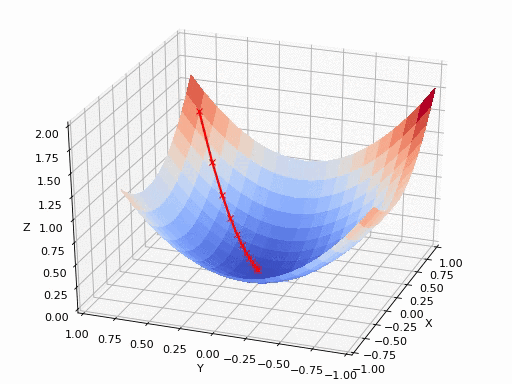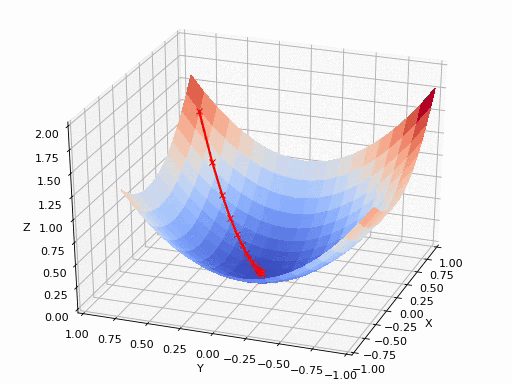
假设在一个类是凹函数的山中放一个小球,让它自然的滚动到山谷(最小值点)处,那么小球滚动每个地点滚动的方向都是梯度的负方向。
现在有一个凹函数,要找到它的最小值,在不考虑解析解的情况下,也可以利用类似的方法去求解。先随机找一个初始点\(x_0\),然后求出该点的梯度,利用公式\(x_1=x_0-lr*\nabla f(x)\)模拟小球的滚动,其中\(lr\)为滚动的步长,也称为学习率。
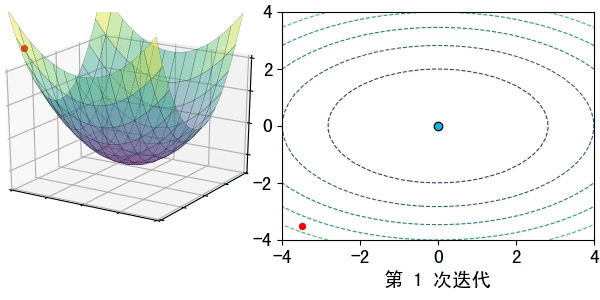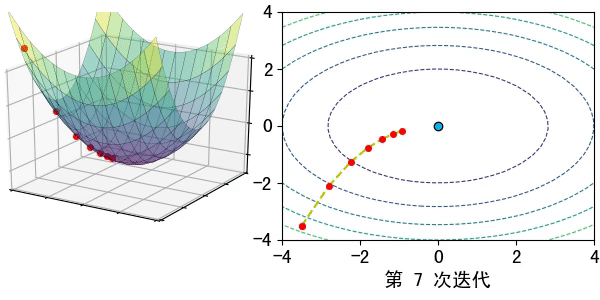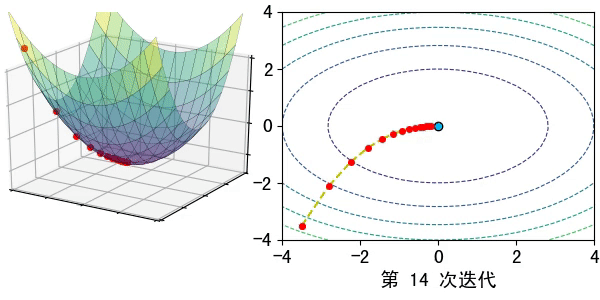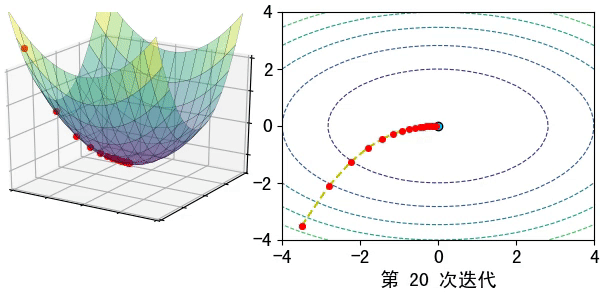
通过迭代公式 \(x_n=x_{n-1}-lr* \nabla f(x)\)一步步去逼近函数的极小值点。通常迭代的结束条件有:
案例 :\(f(x)=(x_1-2)^2+(x_2-3)^2+(x_3-4)^4\)
import numpy as np#定义函数def func(x): return (x[0]-2)**2+(x[1]-3)**2+(x[2]-4)**2#定义梯度def gradFunc(x): return np.array([(x[0]-2)*2,(x[1]-3)*2,(x[2]-4)*2])# 定义梯度下降法def SGD(init_x,func,gradFunc,lr=0.01,maxIter=100000,error=1e-10): x=init_x for iter in range(0,maxIter): gd=gradFunc(x) x_new=x-lr*gd if(np.abs(func(x)-func(x_new))<error): return x_new x=x_new return x_newSGD(np.array([1,1,1]),func,gradFunc) array([1.99998703, 2.99997406, 3.99996109])
SGD(np.array([10,10,10]),func,gradFunc)array([2.00003215, 3.00002813, 4.00002411])
