 ElasticSearch简称es,是一个开源的高扩展的分布式全文检索引擎。它可以近乎实时的存储、检索数据,其扩展性很好,ElasticSearch是企业级应用中较为常见的技术。下面和大家分享 ElasticSearch 集成在Spring Boot 项目的一些学习心得。
ElasticSearch简称es,是一个开源的高扩展的分布式全文检索引擎。它可以近乎实时的存储、检索数据,其扩展性很好,ElasticSearch是企业级应用中较为常见的技术。下面和大家分享 ElasticSearch 集成在Spring Boot 项目的一些学习心得。 ElasticSearch简称es,是一个开源的高扩展的分布式全文检索引擎。
它可以近乎实时的存储、检索数据,其扩展性很好,ElasticSearch是企业级应用中较为常见的技术。
下面和大家分享 ElasticSearch 集成在Spring Boot 项目的一些学习心得。
ElasticSearch 是基于 Lucene 实现的开源、分布式、RESTful接口的全文搜索引擎。
Elasticsearch 还是一个分布式文档数据库,其中每个字段均是被索引的数据且可被搜索,它能够扩展至数以百计的服务器存储以及处理PB级的数据。
Elasticsearch 可以通过简单的 RESTful 风格 API 来隐藏 Lucene 的复杂性,让搜索变得更加简单。
Elasticsearch 的核心概念是 Elasticsearch 搜索的过程,在搜索的过程中,Elasticsearch 的存储过程、数据结构都会有所涉及。
| 关系型数据库 | Elasticsearch |
|---|---|
| 数据库(DataBase) | 索引(indices) |
| 表(table) | types(已弃用) |
| 行(rows) | documents |
| 字段(columns) | fields |
注:
Elasticsearch 中的索引是一个非常大的文档集合,存储了映射类型的字段和其它设置,被存储在各个分片上。
Elasticsearch 使用一种名为倒排索引的结构进行搜索,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。
传统数据库的搜索结构一般以id为主,可以一一对应数据库中的所有内容,即key-value的形式。
而倒排索引则与之相反,以内容为主,将所有不重复的内容记录按照匹配的程度(阈值)进行展示,即value-key的形式。
以下举两个例子来进行说明。
在关系型数据库中,数据是按照id的顺序进行约定的,记录的id具有唯一性,方便人们使用id去确定内容,如表2所示:
| id | label |
|---|---|
| 1 | java |
| 2 | java |
| 3 | java,python |
| 4 | python |
在 ElasticSearch 中使用倒排索引:数据是按照不重复的内容进行约定的,不重复的内容具有唯一性,这样可以快速地找出符合内容的记录,再根据匹配的阈值去进行展示,如表3所示:
| label | id |
|---|---|
| java | 1,2,3 |
| python | 4,3 |
ELK 是 ElasticSearch、Logstash、Kibana这三大开源框架首字母大写简称。
其中 Logstash 是中央数据流引擎,用于从不同目标(文件/数据存储/MQ)中收集不同的数据格式,经过过滤后支持输送到不同的目的地(文件/MQ/Redis/elasticsearch/kafka等)。
而 Kibana 可以将 ElasticSearch 的数据通过友好的可视化界面展示出来,且提供实时分析的功能。
ELK一般来说是一个日志分析架构技术栈的总称,但实际上 ELK 不仅仅适用于日志分析,它还可以支持任何其它数据分析和收集的场景,日志的分析和收集只是更具有代表性,并非 ELK 的唯一用途。
官网地址:https://www.elastic.co
下载地址(7.6.1版本):https://www.elastic.co/downloads/past-releases/elasticsearch-7-6-1,推荐迅雷下载(速度较快)。
将下载好的压缩包进行安装即可,解压后如下图所示: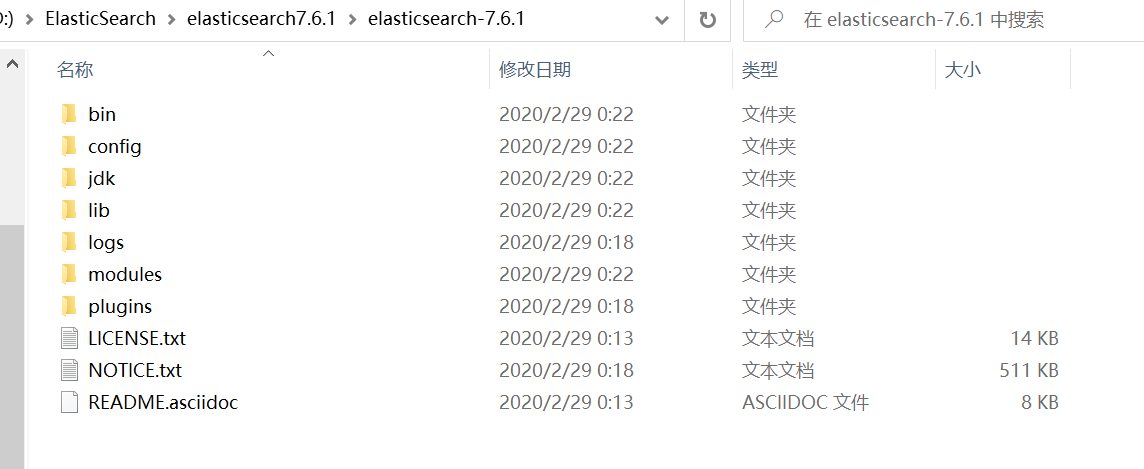
bin 启动文件
config 配置文件
lib 相关jar包
modules 功能模块
plugins 插件(如IK分词器)
打开bin文件夹下的elasticsearch.bat文件,双击启动后访问默认地址:localhost:9200,即可得到以下json格式的数据:
{ "name" : "ZHUZQC", "cluster_name" : "elasticsearch", "cluster_uuid" : "AMdLpCANStmY8kvou9-OtQ", "version" : { "number" : "7.6.1", "build_flavor" : "default", "build_type" : "zip", "build_hash" : "aa751e09be0a5072e8570670309b1f12348f023b", "build_date" : "2020-02-29T00:15:25.529771Z", "build_snapshot" : false, "lucene_version" : "8.4.0", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search"}下载地址:https://github.com/mobz/elasticsearch-head/
安装要求:先检查计算机是否安装node.js、npm
步骤一:在解压后的文件目录下进入cmd,使用 cnpm install 命令安装镜像文件;
步骤二:使用 npm run start 命令启动,得到 http://localhost:9100
步骤三:解决跨域问题,打开 elasticsearch.yml 文件,输入以下代码后保存:
http.cors.enabled: truehttp.cors.allow-origin: "*"再次重启elasticsearch,进入http://localhost:9200 验证是否启动成功
最后进入 http://localhost:9100,得到以下界面,则head启动成功: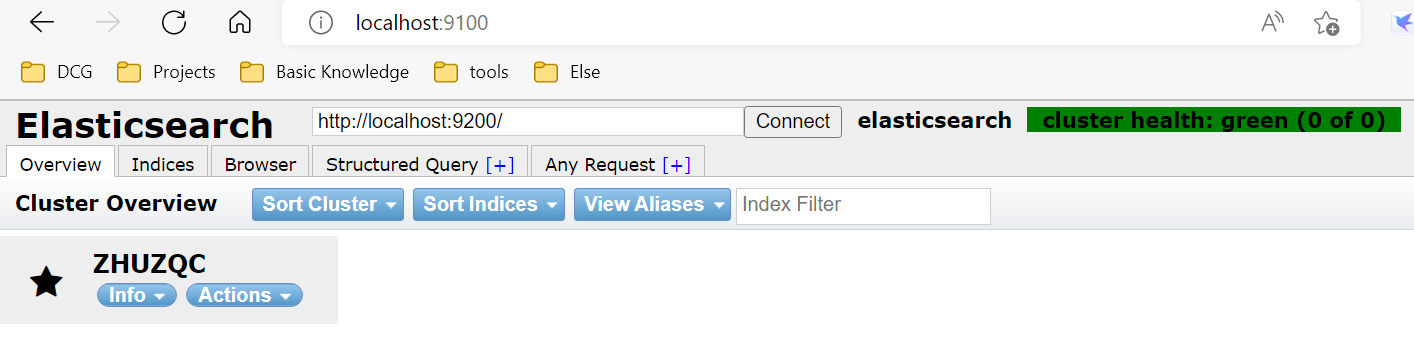
可以把索引当作一个数据库来使用,具体的创建如下步骤所示:
步骤一:点击Indices,在弹出的提示框中填写索引名称,点击确认;
步骤二:可以在head界面中看到该索引,如下图所示: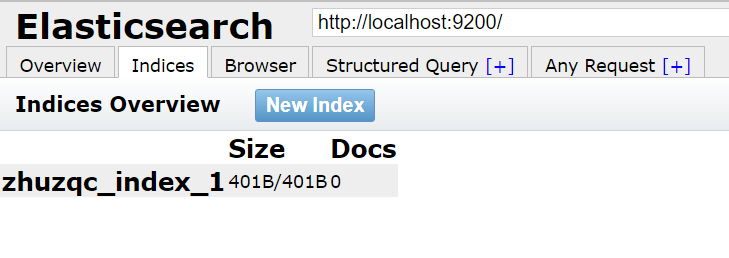
注:head仅可以当作一个数据可视化的展示工具,对于查询语句推荐使用Kibana。
Kibana是一个针对 ElasticSearch 的开源分析、可视化平台,用于搜索、查看交互存储在ElasticSearch中的数据。
Kibana 操作简单,基于浏览器的的用户界面可以快速创建仪表板(dashboard)并实时显示数据。
官网下载:https://www.elastic.co/downloads/past-releases/kibana-7-6-1
注意事项:Kibana 版本需要和 ElasticSearch 的版本保持一致。
安装步骤如下:
在开发的过程中,可供数据测试的工具有很多,比如postman、head、Chrome浏览器等,这里推荐使用 Kibana 进行数据测试。
操作界面如下图所示:
在使用中文进行搜索时,我们会对要搜索的信息进行分词:将一段中文分成一个个的词语或者句子,然后将分出的词进行搜索。
默认的中文分词是一个汉字一个词,如:“你好世界”,会被分成:“你”,“好”,“世”,“界”。但这样的分词方式显然并不全面,比如还可以分成:“你好”,“世界”。
ik分词器就解决了默认分词不全面的问题,可以将中文进行不重复的分词。
ik分词器提供了两种2算法:ik_smart(最少切分)以及ik_max_word(最细颗粒度划分)。
github下载:https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.6.1
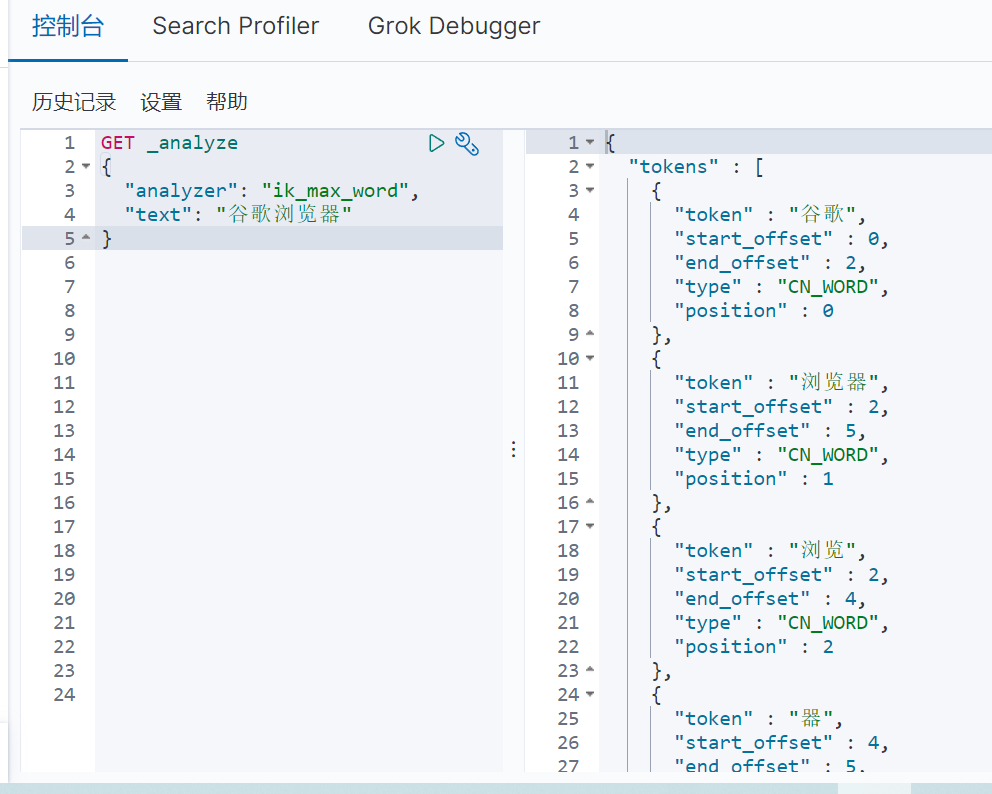
首先测试 ik_smart(最少切分)算法的分词效果,具体如图3-1所示:
再测试 ik_max_word(最细颗粒度划分)算法的分词效果,具体如图3-2所示:
ik分词的默认字典并不能完全涵盖所有的中文分词,当我们想自定义分词时,就需要修改ik分词器的字典配置。
具体效果如下图3-3所示: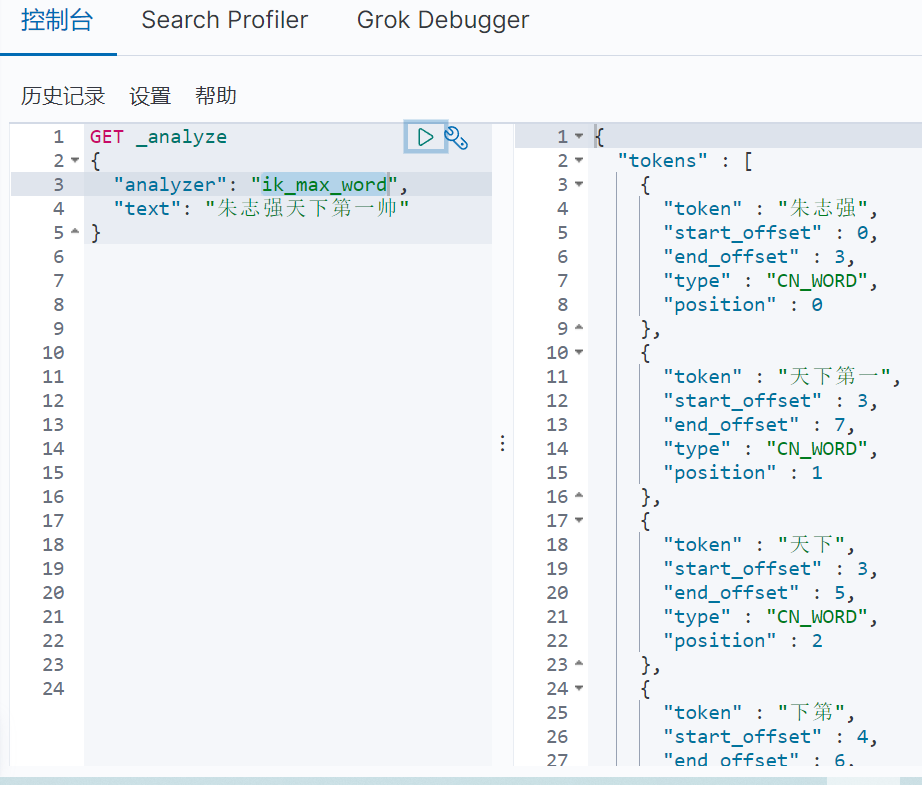
ElasticSearch 使用 Rest 风格来进行一系列操作,具体的命令如图4-1所示: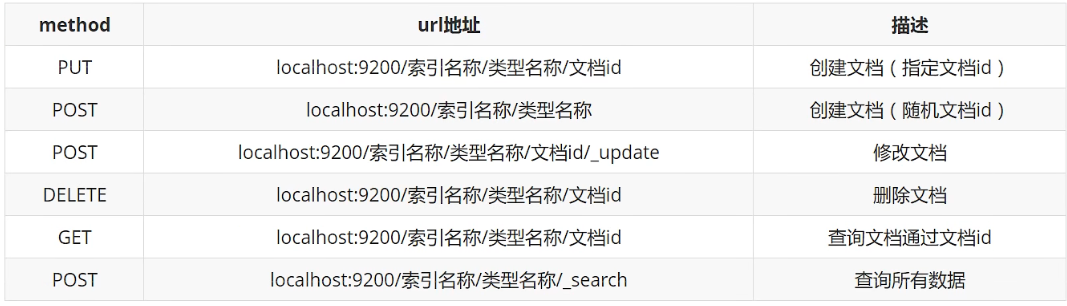
PUT /test_1/type/1{ "name": "zhuzqc", "age": 35364}GET /test_1{ "mappings": { "properties": { "name": { "type": "text" }, "age": { "type": "long" }, "birthdy": { "type": "date" } } }}POST /test_1/_doc/1/_update{ "doc": { "name": "noone" }}DELETE test_2documents 可以看作是数据库中的行记录;
PUT zhuzqc/user/3{ "name": "李四", "age": 894, "desc": "影流之主", "tags": ["劫","刺客","中单"]}2.获取数据:
GET zhuzqc/user/13.更新数据
// POST请求对指定内容进行更新POST zhuzqc/user/1/_update{ "doc": { "name": "342rfd", "age": 243234 }}4.简单的条件查询
// 查询统一GET开头,_search后接?,q代表query,属性:内容GET zhuzqc/user/_search?q=name:李如:查询zhuzqc索引中name为李四的信息,其中李四遵循默认的分词规则GET zhuzqc/user/_search?q=name:李四上述的一些简单查询操作在企业级应用开发中使用地较少,更多地还是使用查询实现复杂的业务。
随着业务的复杂程度增加,查询的语句也随之复杂起来,在使用复杂查询的过程中必然会涉及一些 elasticsearch 的进阶语法。
对于复杂查询的操作在下一章会详细介绍。
ElasticSearch引擎首先分析需要查询的字符串,根据分词器规则对其进行分词。分词之后,才会根据查询条件进行结果返回。
GET product_cloud/_search{ "query": { "bool": { "must": [ { "bool": { "should": [ {"match": {"product_comment":"持续交付 工程师"}} ] } }, { "bool": { "should": [ {"terms": {"label_ids": [3]}} ] } } ], "filter": { "range": { "label_ids": { "gte": 0 } } } } }score 关键字:字段内容与词条的匹配程度,分数越高,表明匹配度越高,就越符合查询结果。
hits 关键字:对应 Java 代码中的 hit 对象,包含了索引和文档信息,包括查询结果总数,查询出来的_doc内容(一串 JSON),分数(score)等。
source:需要展示的内容字段,默认是展示索引的所有字段,也可以自定义指定需要展示的字段。
sort关键字:可以对字段的展示进行排序;
"_source": ["product_comment","product_name","label_ids","product_solution","company_name"], "sort": [ { "label_ids": { "order": "desc" } } ], "from": 0, "size": 3使用 highlight 关键字可以在搜索结果中对需要高亮的字段进行高亮(可自定义样式)展示,具体代码如下:
GET product_cloud/_search{ "query": { "term": { "product_comment": "世界" } }, "highlight": { "pre_tags": "<p class='key' style='color:red'>", "post_tags": "</p>", "fields": { "product_comment": {} } }}在 Elasticsearch 的官方文档中有对 Elasticsearch 客户端使用的详细介绍: https://www.elastic.co/guide/en/elasticsearch/client/java-api-client/8.0/installation.html
<properties> <java.version>11</java.version> <!-- 自定义 ElasticSearch 依赖版本与安装的版本一致 --> <elasticsearch.verson>7.6.1</elasticsearch.verson></properties> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency>定义一个客户端对象:
@Configurationpublic class EsConfig { @Bean public RestHighLevelClient restHighLevelClient(){ RestHighLevelClient restHighLevelClient = new RestHighLevelClient( RestClient.builder( new HttpHost("127.0.0.1",9200,"http") ) ); return restHighLevelClient; }} @Autowired private RestHighLevelClient restHighLevelClient; // 测试索引的创建 @Test void testCreateIndex() throws IOException { //1、创建索引请求 CreateIndexRequest request = new CreateIndexRequest("zhu_index"); //2、执行创建请求,并获得响应 CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT); System.out.println(createIndexResponse); }// 测试获取索引 @Test void testExistIndex() throws IOException { GetIndexRequest getIndexRequest = new GetIndexRequest("zhu_index"); boolean exists = restHighLevelClient.indices().exists(getIndexRequest, RequestOptions.DEFAULT); System.out.println(exists); } // 测试删除索引 @Test void testDeleteIndex() throws IOException { DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest(); AcknowledgedResponse delete = restHighLevelClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT); System.out.println(delete); }API 的操作主要是将Spring Boot项目与 Elasticsearch 的 indices 与 docs 相关联起来,这样可以做到在 Elasticsearch 中对项目数据进行一系列的操作。
// 测试添加文档 @Test void testAddDocument() throws IOException { // 创建对象 User user = new User("zzz",3); // 创建请求 IndexRequest zhu_index_request = new IndexRequest("zhu_index"); // 规则:put /zhu_index/_doc/1 zhu_index_request.id("1"); zhu_index_request.timeout(TimeValue.timeValueSeconds(1)); // 将数据放入 ElasticSearch 请求(JSON格式) zhu_index_request.source(JSON.toJSONString(user), XContentType.JSON); // 客户端发送请求 IndexResponse indexResponse = restHighLevelClient.index(zhu_index_request, RequestOptions.DEFAULT); } // 添加大批量的数据 @Test void testBulkRequest() throws IOException { BulkRequest bulkRequest = new BulkRequest(); bulkRequest.timeout("10s"); //创建数据集合 ArrayList<User> userList = new ArrayList<>(); userList.add(new User("zzz2",22)); userList.add(new User("zzz3",23)); userList.add(new User("zzz4",24)); userList.add(new User("zzz5",25)); userList.add(new User("zzz6",26)); //遍历数据:批量处理 for (int i = 0; i < userList.size(); i++) { // 批量添加(或更新、或删除) bulkRequest.add( new IndexRequest("zhu_index") //.id(""+(i+1)) .source(JSON.toJSONString(userList.get(i)), XContentType.JSON)); } BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT); } @Test void testGetDocument() throws IOException { GetRequest getRequest = new GetRequest("zhu_index","1"); GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT); // 返回_source的上下文 getRequest.fetchSourceContext(new FetchSourceContext(true)); } // 更新文档信息 @Test void testUpdateDocument() throws IOException { UpdateRequest updateRequest = new UpdateRequest("zhu_index","1"); updateRequest.timeout("1s"); User user = new User("ZhuZhuQC",18); updateRequest.doc(JSON.toJSONString(user), XContentType.JSON); UpdateResponse updateResponse = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT); }与添加数据、更新数据类似,创建 DeleteRequest 对象即可。
// 查询数据 @Test void testSearch() throws IOException { // 创建查询对象 SearchRequest searchRequest = new SearchRequest(EsConst.ES_INDEX); // 构建搜索条件(精确查询、全匹配查询) TermQueryBuilder termQuery = QueryBuilders.termQuery("name","zzz2"); MatchAllQueryBuilder matchAllQuery = QueryBuilders.matchAllQuery(); // 执行构造器 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); sourceBuilder.query(termQuery); sourceBuilder.query(matchAllQuery); // 设置查询时间,3秒内 sourceBuilder.timeout(new TimeValue(3, TimeUnit.SECONDS)); // 设置分页 sourceBuilder.from(0); sourceBuilder.size(3); // 最后执行搜索,并返回搜索结果 searchRequest.source(sourceBuilder); SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); searchResponse.getHits(); // 打印结果 System.out.println(JSON.toJSONString(searchResponse.getHits())); for (SearchHit documentFields : searchResponse.getHits().getHits()) { System.out.println(documentFields.getSourceAsMap()); } }实战部分会模拟一个真实的 ElasticSearch 搜索过程:从创建项目开始,到使用爬虫爬取数据、编写业务,再到前后端分离交互,最后搜索结果高亮展示。
创建项目的步骤可如以下几步:
<properties> <java.version>11</java.version> <!-- 自定义 ElasticSearch 依赖版本与安装的版本一致 --> <elasticsearch.version>7.6.1</elasticsearch.version> </properties> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.83</version> </dependency>server.port=9090# 关闭 thymeleaf 缓存spring.thymeleaf.cache=false#mysql连接配置spring.datasource.username=rootspring.datasource.password=password123spring.datasource.url=jdbc:mysql://localhost:3306/elasticsearch-test?useSSL=false&useUnicode=true&characterEncoding=utf-8spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver#mybatis-plus日志配置mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl#mybatis-plus逻辑删除配置,删除为1,未删除为0mybatis-plus.global-config.db-config.logic-delete-value = 1mybatis-plus.global-config.db-config.logic-not-delete-value = 0这个步骤可以在网盘
地址:https://pan.baidu.com/s/1yk_yekYoGXCuO0dc5B-Ftg
密码: rwpq
获取对应的 zip 包,里面包括了一些前端的静态资源和样式,直接放入 resources 文件夹中即可。
@Controllerpublic class IndexController { @GetMapping({"/","/index"}) public String index(){ return "index"; }}在真实的项目中,数据可以从数据库获得,也可以从MQ(消息队列)中获得,也可以通过爬取数据(爬虫)获得,在这里介绍一下使用爬虫获取项目所需数据的过程。
<!--网页解析依赖--> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.11.2</version> </dependency>@Componentpublic class HtmlParseUtil { public static List<Content> parseJD(String keyword) throws IOException { // 1、获取请求:https://search.jd.com/Search?keyword=java String reqUrl = "https://search.jd.com/Search?keyword=" + keyword; // 2、解析网页,返回的document对象就是页面的 js 对象 Document document = Jsoup.parse(new URL(reqUrl), 30000); // 3、js 中使用的方法获取页面信息 Element j_goodList = document.getElementById("J_goodsList"); // 4、获取所有的 li 元素 Elements liElements = j_goodList.getElementsByTag("li"); //5、返回List封装对象 ArrayList<Content> goodsList = new ArrayList<>(); //5、获取元素中的内容,遍历的 li 对象就是每一个 li 标签 for (Element el : liElements) { String price = el.getElementsByClass("p-price").eq(0).text(); String title = el.getElementsByClass("p-name").eq(0).text(); String img = el.getElementsByTag("img").eq(0).attr("data-lazy-img"); // 将爬取的信息放入 List 对象中 Content content = new Content(); content.setTitle(title); content.setImg(img); content.setPrice(price); goodsList.add(content); } return goodsList; }}要编写的业务只有两部分:1、将上述获取的数据放入 ElasticSearch 的索引中;2、实现 ElasticSearch 的搜索功能;
1.controller层:
@Autowired private ContentService contentService; @GetMapping("/parse/{keyword}") public Boolean parse(@PathVariable("keyword") String keyword) throws IOException { return contentService.parseContent(keyword); }2.service层:
@Autowired private RestHighLevelClient restHighLevelClient; /** * 1、将解析后的数据放入 ElasticSearch 的索引中 * */ public Boolean parseContent(String keyword) throws IOException { List<Content> contents = new HtmlParseUtil().parseJD(keyword); //批量插入 es BulkRequest bulkRequest = new BulkRequest(); bulkRequest.timeout("2m"); for (int i = 0; i < contents.size(); i++) { bulkRequest.add( new IndexRequest("jd_goods") .source(JSON.toJSONString(contents.get(i)), XContentType.JSON) ); } BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT); return bulk.hasFailures(); }1.controller层:
@GetMapping("/search/{keyword}/{pageNo}/{pageSize}") public List<Map<String, Object>> search(@PathVariable("keyword") String keyword, @PathVariable("pageNo") Integer pageNo, @PathVariable("pageSize") Integer pageSize) throws IOException { return contentService.searchPage(keyword, pageNo, pageSize); }2.service层:
/** * 2、获取数据后实现搜索功能 * */ public List<Map<String,Object>> searchPage(String keyword, Integer pageNo, Integer pageSize) throws IOException { if (pageNo <= 1){ pageNo = 1; } //条件搜索 SearchRequest searchRequest = new SearchRequest("jd_goods"); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); //精准匹配 TermQueryBuilder titleTermQuery = QueryBuilders.termQuery("title", keyword); sourceBuilder.query(titleTermQuery); sourceBuilder.timeout(new TimeValue(3, TimeUnit.SECONDS)); //分页 sourceBuilder.from(pageNo); sourceBuilder.size(10); //执行搜索 searchRequest.source(sourceBuilder); SearchResponse searchResponse = restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT); //解析结果 ArrayList<Map<String, Object>> list = new ArrayList<>(); for (SearchHit documentFields : searchResponse.getHits().getHits()) { list.add(documentFields.getSourceAsMap()); } return list; }前后端交互主要是通过接口查询数据并返回:前端有请求参数(关键字、分页参数)后,后端通过关键字去 elasticsearch 索引中进行筛选,最终将结果返回给前端现实的一个过程。
在这里主要分析一下前端是怎么获得后端接口参数的,后端的接口在上述业务编写中已经包含了。
<!--前端使用Vue--><script th:src="@{/js/axios.min.js}"></script><script th:src="@{/js/vue.min.js}"></script><script> new Vue({ el: '#app', data:{ // 搜索关键字 keyword: '', //返回结果 results: [] } })</script><script> methods: { searchKey(){ let keyword = this.keyword; console.log(keyword); //对接后端接口:关键字、分页参数 axios.get('search/' + keyword + '/1/20').then(response=>{ console.log(response); //绑定数据 this.results = response.data; }) } }</script>关键字高亮总结来说,就是将原来搜索内容中的关键字置换为加了样式的关键字,进而展示出高亮效果。
主要逻辑在于,获取到 Hits 对象后,遍历关键字字段,将高亮的关键字重新放入 Hits 集合中。
具体代码如下:
//解析结果 ArrayList<Map<String, Object>> list = new ArrayList<>(); for (SearchHit documentFields : searchResponse.getHits().getHits()) { //解析高亮字段,遍历整个 Hits 对象 Map<String, HighlightField> highlightFields = documentFields.getHighlightFields(); //获取到关键字的字段 HighlightField title = highlightFields.get("title"); Map<String, Object> sourceAsMap = documentFields.getSourceAsMap(); //置换为高亮字段:将原来的字段替换为高亮的字段 if(title != null){ Text[] fragments = title.fragments(); //定义新的高亮字段 String new_title = ""; for (Text text : fragments) { new_title += text; } //将高亮的字段放入 Map 集合 sourceAsMap.put("title",new_title); } list.add(sourceAsMap); }ElasticSearch 作为一个分布式全文检索引擎,也可以应用在集群当中(K8S、Docker)。
ElasticSearch 实现全文检索的过程并不复杂,只要在业务需要的地方创建 ElasticSearch 索引,将数据放入索引中,就可以使用 ElasticSearch 集成在各个语言中的搜索对象进行查询操作了。
而在集成了 ElasticSearch 的 Spring Boot 项目中,无论是创建索引、精准匹配、还是字段高亮等,都是使用 ElasticSearch 对象在操作,本质上还是一个面向对象的过程。
和 Java 中的其它“对象”一样,只要灵活运用这些“对象”的使用规则和特性,就可以满足业务上的需求,对这个过程的把控也是工程师能力 的一种体现。
在 Spring Boot 项目中集成 ElasticSearch 就和大家分享到这里,如有不足,还望大家不吝赐教!
