
怎么利用大厂的API将大段音频转成文本
日常办公中,我们经常要开会和写会议纪要。传统模式下,我们需要非常认真地听会议中每一句话,记下自己认为的核心的话,并在会后经过多次修改形成会议纪要。现在,聪明人已 经不那么干了,借助几百块的讯飞录音笔,我们可以一口气录下长达三小时的音频,讯飞还能免费给这些录音笔录制的音频转成文本,且识别率相当高,可谓非常方便。
不过,假如我们没买录音笔,没借到这样的录音笔或者刚好忘了带,最后只能借助用机来录音的时候,面对这样的音频,该怎么低价、快速转文本,方便我们最后写会议纪要之类的东东呢?
有钱有VIP的话,这不是问题。比如讯飞听见,报价是0.33元/分钟,差不多20块一个小时,其他厂商提供的To C端的服务,基本价格也是大差不差。如果小爬没有更省钱的方法,自然就不会有这篇博文了。接下来讲讲怎么用厂商API来实现大段的音频转文本。
这里以百度智能云提供的API接口为例,且看小爬如何写Python脚本,利用这些API,实现低价的音频转文本。看了下百度智能云的官网提供的服务,关于语音识别这块,大概的AI能力有这些:
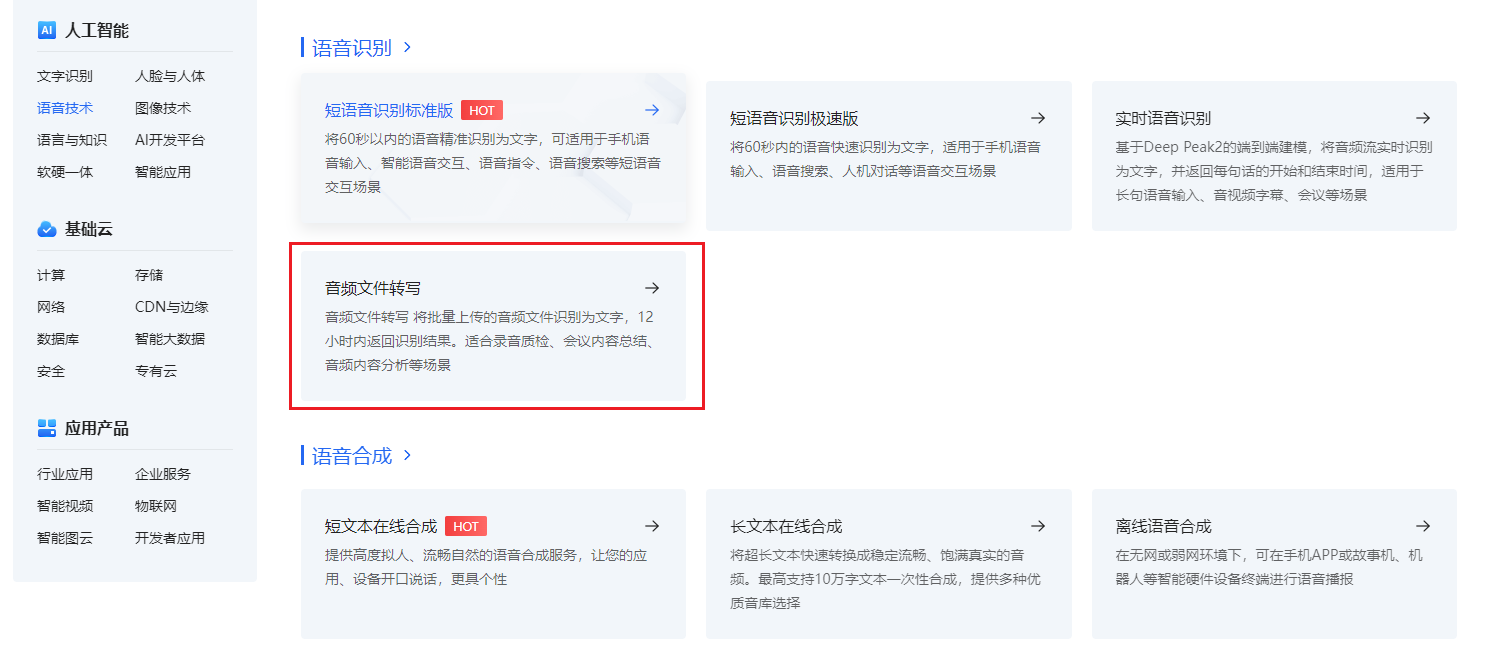
基于上面提到的场景,我们需要借助的是【音频文件转写】的能力,我们再简单看下价格,如下图所示:
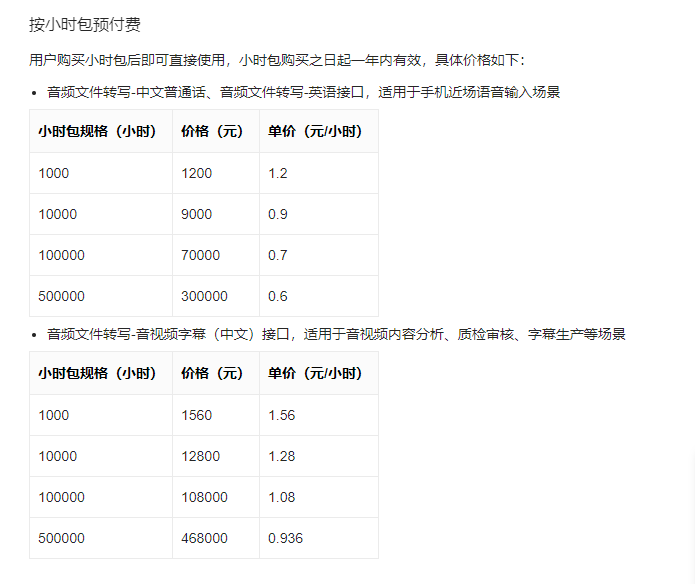
计价方式多样,但是总结就是两句话:用的越多价格越低,最高单价也就是1.56元/时。看上去比To C的那些语音转文本的价格实惠多了。那还等什么,赶紧把代码整起来呗?
写代码前,我们需要看看它的技术文档:语音技术 (baidu.com),这里面不仅有接口API,还提供的python的Demo示例。但是你要指望这Demo能直接用,就太天真了。
简单点说,我们需要先在百度智能云上【音频文件转写】的详情页,点击【立即使用】,按照说明,新建一个应用,勾选上需要的AI能力,这样,我们就可以拿到百度给这个应用独有的API_KEY以及SECRET_KEY。
由于音频很长,所以转文本需要一定的时间,百度给的接口做成异步的了。也就是说我们需要两个脚本,其中一个用来创建转音频的任务,另一个脚本用来请求结果。先来魔改官方给的Demo示例来创建任务,每次的请求之前,我们需要向API接口拿到单次请求的Token,获取Access_token的代码大概如下:
import requests,json,time,ssl from urllib.request import urlopen,Request from urllib.error import URLError from urllib.parse import urlencode timer = time.perf_counter ssl._create_default_https_context = ssl._create_unverified_context 填写百度控制台中相关开通了“音频文件转写”接口的应用的的API_KEY及SECRET_KEY API_KEY = 'Your API Key' SECRET_KEY = 'Your Secret Key' """ 获取请求TOKEN start 通过开通音频文件转写接口的百度应用的API_KEY及SECRET_KEY获取请求token""" class DemoError(Exception): pass TOKEN_URL = 'https://openapi.baidu.com/oauth/2.0/token' SCOPE = 'brain_bicc' 有此scope表示有asr能力,没有请在网页里勾选 bicc SCOPE = 'brain_asr_async' 有此scope表示有asr能力,没有请在网页里勾选 SCOPE = 'brain_enhanced_asr' 有此scope表示有asr能力,没有请在网页里勾选 def fetch_token(): params = {'grant_type': 'client_credentials', 'client_id': API_KEY, 'client_secret': SECRET_KEY} post_data = urlencode(params) post_data = post_data.encode( 'utf-8') req = Request(TOKEN_URL, post_data) try: f = urlopen(req) result_str = f.read() except URLError as err: print('token http response http code : ' + str(err.code)) result_str = err.read() result_str = result_str.decode() print(result_str) result = json.loads(result_str) print(result) if ('access_token' in result.keys() and 'scope' in result.keys()): if not SCOPE in result['scope'].split(' '): raise DemoError('scope is not correct') print('SUCCESS WITH TOKEN: %s ; EXPIRES IN SECONDS: %s' % (result['access_token'], result['expires_in'])) return result['access_token'] else: raise DemoError('MAYBE API_KEY or SECRET_KEY not correct: access_token or scope not found in token response') """ 获取鉴权结束,TOKEN end """
拿到Access_Token后,我们就可以根据API创建任务了,示例代码如下:
""" 发送识别请求 """ 待进行语音识别的音频文件url地址,需要可公开访问。建议使用百度云对象存储(https://cloud.baidu.com/product/bos.html) def create_task(speech_url): url = 'https://aip.baidubce.com/rpc/2.0/aasr/v1/create' 创建音频转写任务请求地址 body = { "speech_url": speech_url, "format": "wav", 音频格式,支持pcm,wav,mp3,音频格式转化可通过开源ffmpeg工具(https://ai.baidu.com/ai-doc/SPEECH/7k38lxpwf)或音频处理软件 "pid": 1537, 模型pid,1537为普通话输入法模型,1737为英语模型 "rate": 16000 音频采样率,支持16000采样率,音频格式转化可通过开源ffmpeg工具(https://ai.baidu.com/ai-doc/SPEECH/7k38lxpwf)或音频处理软件 } token = {"access_token":fetch_token()} headers = {'content-type': "application/json"} response = requests.post(url,params=token,data = json.dumps(body), headers = headers) 返回请求结果信息,获得task_id,通过识别结果查询接口,获取识别结果 textMsg=response.json() print(textMsg) return textMsg.get("task_id")
需要注意的是,该API不支持读本地的音频文件,而是要求提起将音频上传到公网上,要支持公开访问,这个方法中的Speech_url参数,它指的是待进行语音识别的音频文件url地址,官方建议使用百度云对象存储(https://cloud.baidu.com/product/bos.html),不过小爬在写这个例子的时候,这个官网莫名其妙加载非常慢,体验很差,具体原因不详,最好小爬只好选择了其他厂商的类似服务,比如七牛云。不用担心,对于普通用户,有10GB的免费的每月存储空间。另外,这个方法最终可以返回任务的Task_id,它的重要性不言而喻,我们就是通过它来得到最终的结果。
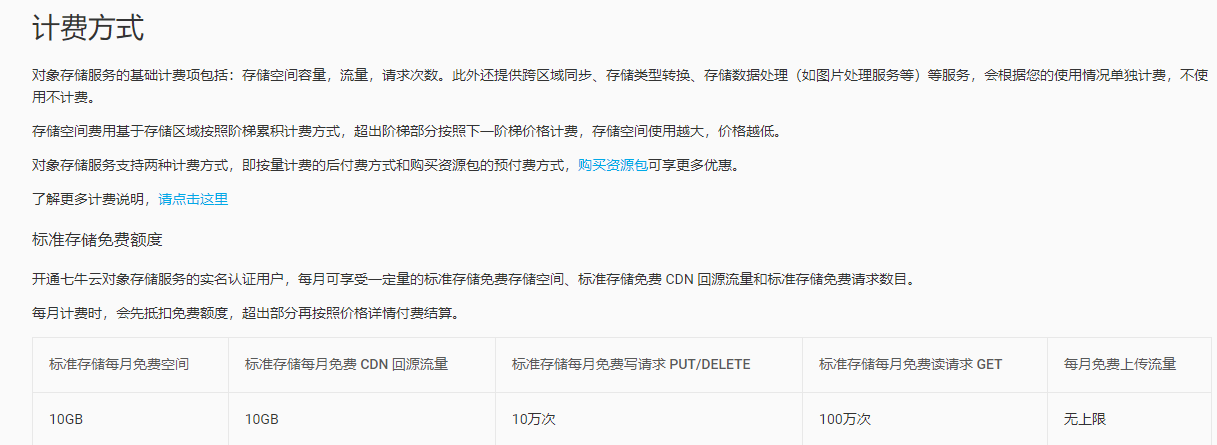
开通七牛云账号之后,我们按照提示,将待转的音频存储到七牛云存储服务器 公开路径。限于篇幅,小爬对具体的操作就不过多赘述了。这里必须是公开路径,否则百度的API没法访问私有的七牛云生成的存储音频的URL。你在担心信息暴露了对不对?哈哈,你的URL不到处分享,即使在公网上,也不会有人知道的。另外,如果实在担心,我们可以利用它创建完任务并成功转为文本后,再去账号上删除这段音频,这下顾虑可以打消了吧?
万事俱备后,我们需要结合查看结果的api来获取最终的文本,对了,获取结果的API,同样是需要事先申请Token的,您需要再次借助上面提到的fetch_token方法。当token和task_id都准备好之后,剩下的事儿就简单多了,示例如下:
""" 发送查询结果请求 """ 转写任务id列表,task_id是通过创建音频转写任务时获取到的,每个音频任务对应的值 task_id_list = [ "task_id", ] for task_id in task_id_list: url = 'https://aip.baidubce.com/rpc/2.0/aasr/v1/query' 查询音频任务转写结果请求地址 body = { "task_ids": [task_id], } token = {"access_token":fetch_token()} headers = {'content-type': "application/json"} response = requests.post(url,params=token,data = json.dumps(body), headers = headers) print(json.dumps(response.json(), ensure_ascii=False))
赶紧学起来吧,可以帮您省下好多银子呢,这些银子用来干啥不香呢?如果您技术过硬,还可以利用大厂的这些api搭建自己的AI服务,创建自己的【语音转文本】To C产品,这差价不是挣得美滋滋?
快来关注本公众号 获取更多爬虫、数据分析的知识!
