摘要:本文介绍了循环码和卷积码两种编码方式,并且,作者给出了两种编码方式的编码译码的python实现
关键字:循环码,系统编码,卷积码,python,Viterbi算法
设 \(C\) 是一个 \(q\) 元 \([n,n-r]\) 循环码,其生成多项式为\(g(x), \text{deg}(g(x))=r\)。显然,\(C\) 有 \(n-r\) 个信息位,\(r\) 个校验位。我们用 \(C\) 对信息源 \(V(n-r,q)\) 中的向量进行表示。
对任意信息源向量 \(a_0a_1\cdots a_{n-r-1}\in V(n-r,q)\),循环码有两种编码思路:
构造信息多项式
该信息源的多项式对应于循环码 \(C\) 的一个码字
构造信息多项式
显然当 \(a_0,a_1,\cdots,a_{n-r-1}\) 不全为零时。\(r\lt\text{deg}(\bar{a}(x))=n-1\)。用 \(g(x)\) 去除 \(\bar{a}(x)\),得到
其中 \(\text{deg}(r(x))\lt\text{deg}(g(x))=r\),信息源多项式被编码为C中的码字
可以看到,\(\bar{a}(x)\) 和 \(r(x)\) ,没有相同的项,所以这种编码方式为系统编码。也即,如果将 \(c(x)\) 中的 \(x\) 的项按生降次排序,则码字前 \(n-r\) 位就是信息位,后 \(r\) 位是校验位。
已知 \(C\) 是一个二元 \((7,4)\) 循环码,生成多项式为 \(g(x)=x^3+x+1\)。
\(0101\in V(4,2)\) 是代编码的信息向量
也即,\(0101\in V(4,2)\) 被编码为\(0111001\in V(7,2)\)
也就是,\(0101\in V(4,2)\) 被编码为\(0101100\in V(7,2)\)
一般而言,系统码解码速度相比非系统编码更快。接下来我们对上述例子进一步探索。
考虑 \(F_2[x]/\langle x^7-1\rangle\) 中阶数大于3的基。
也即,\(1000\in V(4,2)\) 被编码为\(1000101\in V(7,2)\)。
也即,\(0100\in V(4,2)\) 被编码为\(0100111\in V(7,2)\)。
也即,\(0010\in V(4,2)\) 被编码为\(0010110\in V(7,2)\)。
也即,\(0001\in V(4,2)\) 被编码为\(0001011\in V(7,2)\)。
所以生成多项式为 \(g(x)=x^3+x+1\) 的 \((7,4)\) 循环码C的生成矩阵为
首先我们不加证明的引入循环矩阵的校验多项式核校验矩阵的知识。
定义 设 \(C\subset R_n\) 是一个 \(q\) 元 \([n,n-r]\) 循环码,其生成多项式为 \(g(x)\),校验多项式定义为
定理 设 \(C\subset R_n\) 是一个 \(q\) 元 \([n,n-r]\) 循环码,其生成多项式为 \(g(x)\),校验多项式为 \(h(x)\),则对任意 \(c(x)\in R_n(x)\),\(c(x)\) 是 \(C\) 的一个码字当且仅当 \(c(x)h(x)=0\)。
定理 设\(C\subset R_n\) 是一个 \(q\) 元 \([n,n-r]\) 循环码,其生成多项式为 \(g(x)\),校验多项式记为
且其校验矩阵为
所以可得,对于已知 \(C\) 是一个二元 \((7,4)\) 循环码,生成多项式为 \(g(x)=x^3+x+1\),校验多项式为 \(h(x)=x^4+x^3+x^2+1\),校验矩阵为
因为是系统编码,所以,如果将 \(c(x)\) 中的 \(x\) 的项按降幂次排序,则码字前 \(n-r\) 位就是信息位,后 \(r\) 位是校验位。也就是,如果不出错,则接受的的码字的前 4 个''字母''(信息比特)就是对方传输的信息。
但是考虑到一般情形,二元循环码解码流程如下
对于上述码字,若接收到 \(y=0110010\),\(S(y)=yH^T=011=1*H_4\),所以发送码字为 \(0111010\),也即代表信息源 \(0111\)。
对于上述循环码,python程序实现如下
# (7,4)二元循环码# 生成多项式 g(x)= x^3+x+1import numpy as np# 生成矩阵G = np.array([ [1,0,0,0,1,0,1], [0,1,0,0,1,1,1], [0,0,1,0,1,1,0], [0,0,0,1,0,1,1]])# 校验矩阵H = np.array([ [1,1,1,0,1,0,0], [0,1,1,1,0,1,0], [0,0,1,1,1,0,1]])# 编码def encode_cyclic(x): if not len(x) == 4: print("请输入4位信息比特") return y = np.dot(x,G) print(x,"编码为:",y) return y# 译码,过程与汉明码一致def decode_cyclic(y): if not len(y) == 7: print("请输入7位信息比特") return x_tmp = np.dot(y,H.T)%2 if (x_tmp!=0).any(): for i in range(H.shape[1]): if (x_tmp==H[:,i]).all(): y[i] = (y[i]-1)%2 break x = y[0:4] print(y,"解码为:",x) return x# 测试if __name__ == '__main__': y = [1,0,0,0,1,0,1] decode_cyclic(y) x=[1,0,0,0] encode_cyclic(x)卷积码是信道编码技术的一种,属于一种纠错码。最早由1955年Elias最早提出,目的是为了减少在信源消息在信道传输过程中产生的差错,增加接收端译码的准确性。
卷积码的生成方式是将待传输的信息序列通过线性有限状态移位寄存器,也就是在卷积码的编码过程中,需要输入消息源与编码器中的冲激响应做卷积。具体说来,在任意时段,编码器的 \(n\) 个输出不仅与此时段的 \(k\) 个输入有关,还与寄存器中前 \(m\) 个输入有关。卷积码的纠错能力随着 \(m\) 的增加而增大,同时差错率随着 \(m\) 的增加而成指数下降。
参数 \((n,k,m)\) 解释如下:
由此看来,卷积码编码的结果与之前的输入有关,编码具有记忆性,是非分组码。而分组码的编码只于当前输入有关,编码不具有记忆性。
1967年Viterbi提出基于动态规划的最大似然Viterbi译码法。
如下图为:(2,1,2)卷积码的编码示意图
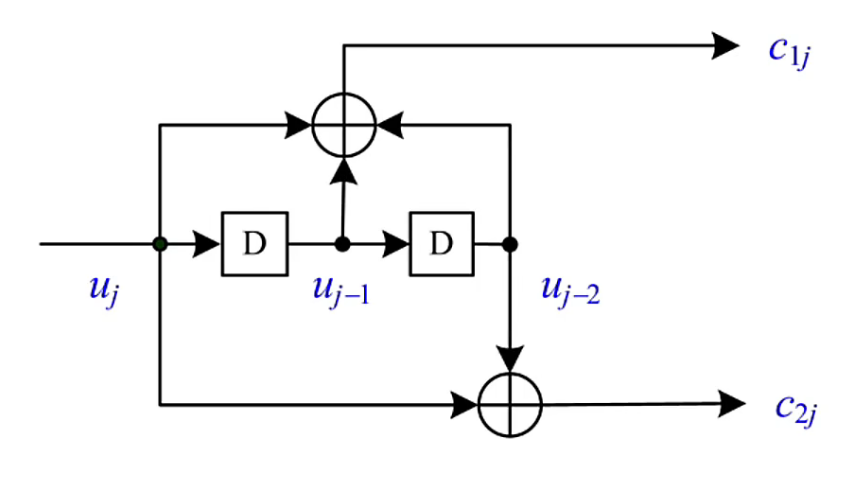
其中,\(j\) 表示时序,
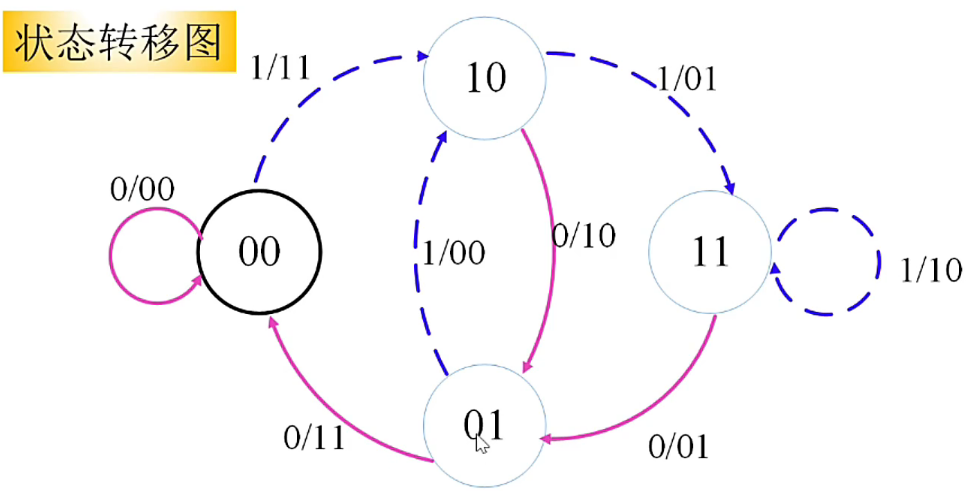
为了后续说明卷积码中重要的“状态”概念,现引入记号(仅以2个输出为例,\(n\) 个输出可以此类推):
所以不难看出(2,1,2)卷积码由 4 种可能的状态,为 \((00),(01),(10),(11)\)。
对于状态我们有如下引理
引理
给定出发状态 \(s_{j-1}\) 和当前的输入 \(u_j\),可以确定出到达状态 \(s_j\) 以及当前输出 \(c_{1_j}c_{2j}\)
给定状态的变化序列 \(s_0s_1s_2\cdots\),将能确定出输入序列 \(u_0u_1u_2\cdots\) 以及输出序列\(c_{10}c{20}c_{11}c_{21}\cdots\)
注:我们默认初始状态\(s_{-1}=0\)
从上述描述中,不难看出,卷积码的全部信息都包含在状态变化序列中。
下图为“格图”,
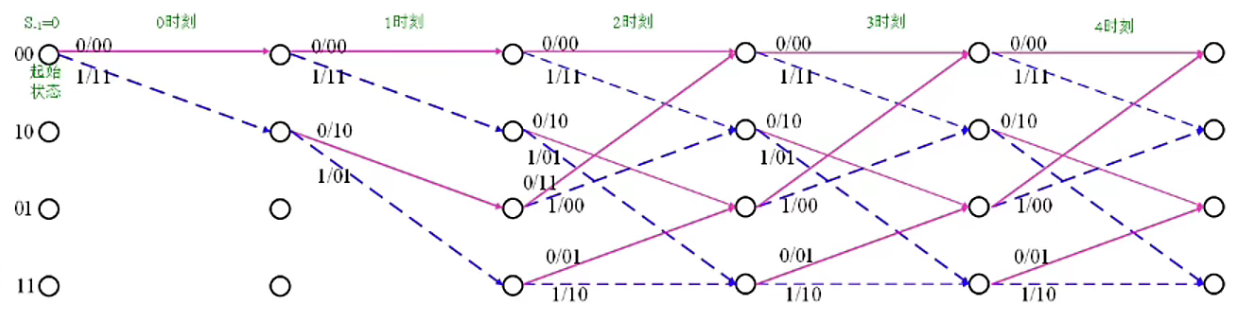
格图结构更加紧凑,代表着时间的移动,也即,信息比特在不断输入。
从上图中,我们可得出,若输入序列是 \(10110\),则输出序列为 \(11 10 00 01 01\)。
代码示例如下
# (2,1,2)卷积码# 卷积编码def encode_conv(x): # 存储编码信息 y = [] # 两个寄存器u_1 u_2初始化为0 u_2 = 0 u_1 = 0 for j in x: c_1 = (j + u_1 + u_2)%2 c_2 = (j+u_2)%2 y.append(c_1) y.append(c_2) # 更新寄存器 u_2 = u_1 u_1 = j print(x,"编码为:",y) return y# 测试代码if __name__ == '__main__': encode_conv([1,0,1,1,0])我们注意到
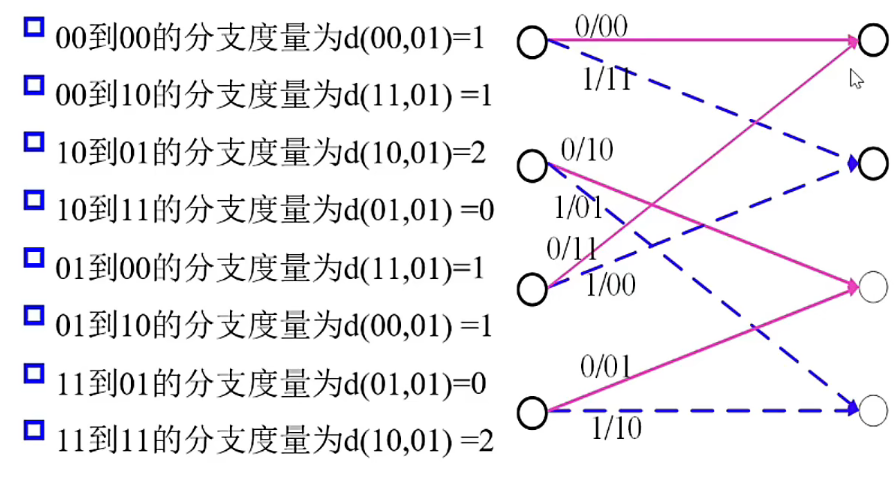
设 \(j\) 时刻接受的比特是 \(y_{1j}y_{2j}\)
例如从第 \(i\) 步到第 \((i+1)\) 步接收的比特位 \(01\)
如下为输入比特:01 11 01 的格图。
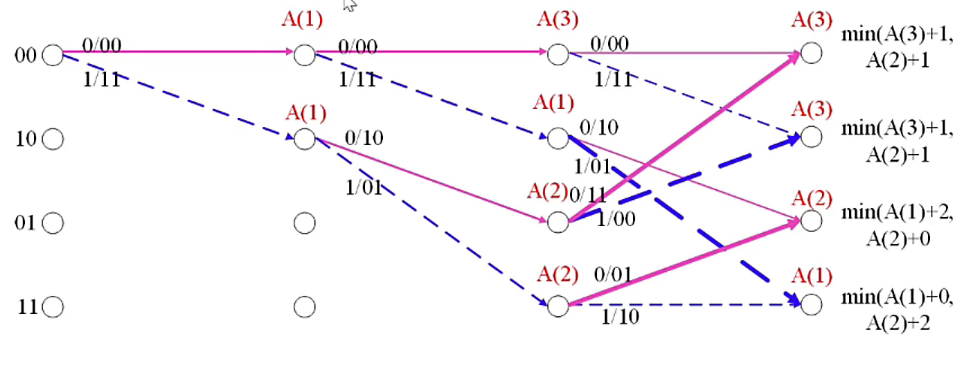
其中 \(A(i)\) 表示从开始时刻到当前时刻的累积度量为 \(i\)
对于接收序列为:01 11 01 11 00
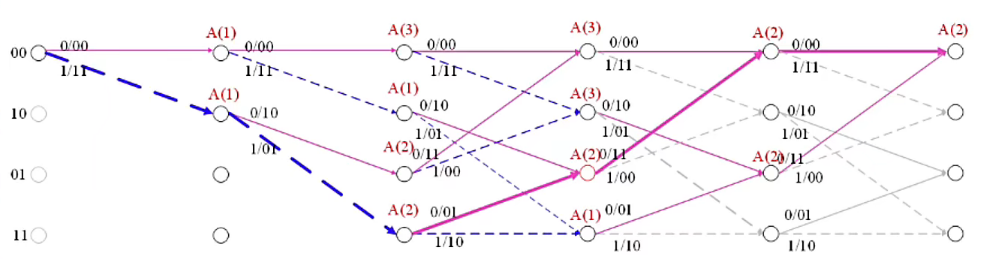
通过上述路径分析图可得,经过最大似然译码分析后,译码序列为:11000
Viterbi译码python实现如下:
def decode_conv(y): # shape = (4,len(y)/2) # 初始化 score_list = np.array([[ float('inf') for i in range(int(len(y)/2)+1)] for i in range(4)]) for i in range(4): score_list[i][0]=0 # 记录回溯路径 trace_back_list = [] # 每个阶段的回溯块 trace_block = [] # 4种状态 0-3分别对应['00','01','10','11'] states = ['00','01','10','11'] # 根据不同 状态 和 输入 编码信息 def encode_with_state(x,state): # 编码后的输出 y = [] u_1 = 0 if state<=1 else 1 u_2 = state%2 c_1 = (x + u_1 + u_2)%2 c_2 = (x + u_2)%2 y.append(c_1) y.append(c_2) return y # 计算汉明距离 def hamming_dist(y1,y2): dist = (y1[0]-y2[0])%2 + (y1[1]-y2[1])%2 return dist # 根据当前状态now_state和输入信息比特input,算出下一个状态 def state_transfer(input,now_state): u_1 = int(states[now_state][0]) next_state = f'{input}{u_1}' return states.index(next_state) # 根据不同初始时刻更新参数 # 也即指定状态为 state 时的参数更新 # y_block 为 y 的一部分, shape=(2,) # pre_state 表示当前要处理的状态 # index 指定需要处理的时刻 def update_with_state(y_block,pre_state,index): # 输入的是 0 encode_0 = encode_with_state(0,pre_state) next_state_0 = state_transfer(0,pre_state) score_0 = hamming_dist(y_block,encode_0) # 输入为0,且需要更新 if score_list[pre_state][index]+score_0<score_list[next_state_0][index+1]: score_list[next_state_0][index+1] = score_list[pre_state][index]+score_0 trace_block[next_state_0][0] = pre_state trace_block[next_state_0][1] = 0 # 输入的是 1 encode_1 = encode_with_state(1,pre_state) next_state_1 = state_transfer(1,pre_state) score_1 = hamming_dist(y_block,encode_1) # 输入为1,且需要更新 if score_list[pre_state][index]+score_1<score_list[next_state_1][index+1]: score_list[next_state_1][index+1] = score_list[pre_state][index]+score_1 trace_block[next_state_1][0] = pre_state trace_block[next_state_1][1] = 1 if pre_state==3 or index ==0: trace_back_list.append(trace_block) # 默认寄存器初始为 00。也即,开始时刻,默认状态为00 # 开始第一个 y_block 的更新 y_block = y[0:2] trace_block = [[-1,-1] for i in range(4)] update_with_state(y_block=y_block,pre_state=0,index=0) # 开始之后的 y_block 更新 for index in range(2,int(len(y)),2): y_block = y[index:index+2] for state in range(len(states)): if state == 0: trace_block = [[-1,-1] for i in range(4)] update_with_state(y_block=y_block,pre_state=state,index=int(index/2)) # 完成前向过程,开始回溯 # state_trace_index 表示 开始回溯的状态是啥 state_trace_index = np.argmin(score_list[:,-1]) # 记录原编码信息 x = [] for trace in range(len(trace_back_list)-1,-1,-1): x.append(trace_back_list[trace][state_trace_index][1]) state_trace_index = trace_back_list[trace][state_trace_index][0] x = list(reversed(x)) print(y,"解码为:",x) return x # 测试代码if __name__ == '__main__': # 对应 1 1 0 0 0 decode_conv([0,1,1,1,0,1,1,1,0,0])参考
(7,3)循环码编码译码 C实现
卷积编码及维特比译码 - mdnice 墨滴
有噪信道编码—线性分组码_哔哩哔哩_bilibili
